XQUERY и XPATH
Для навигации по дереву XML используется несколько языков - XQUERY и XPATH. Они активно используются в двух местах - при XSLT- преобразованиях и и при использовании SQLXML (описание Шульгина,Microsoft.com). XQUERY в приниципе ОЧЕНЬ похож на XPATH но имеет несколько важных отличий. Важно понимать, что оба этих языка позволяют выполнять так же отборы по XML-документу, как и язык SQL позвляет отбирать реляционные данные.
Меня при первом знакомстве синтаксис и логика этого языка очень удивили - чем и вызвано появление этой странички на моем сайте.
Рассмотрим язык Xpath подробнее - вот первые три строки определения этого языка в нотации Бэкуса-Науэра:

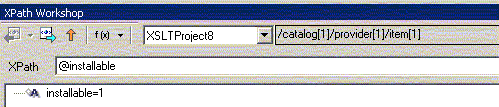
Смысл первого определения в том, что мы можем двигаться по дереву XML-документа от текущего узла /catalog[1]/provider[1]/item[1] либо с помощью относительной, либо с помощью абсолютной адресации
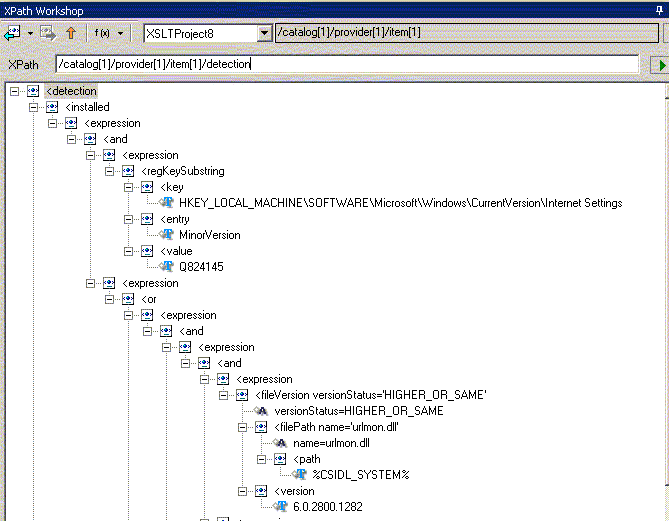
Введем в Xpath Workshop имя узла с предшествующим символом "/" - т.е. выберем дочернее дерева XML-документа с помощью абсолютной адресации:
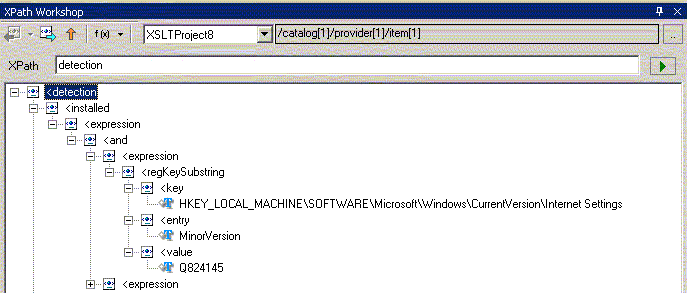
а вот выбор того же дочернего XML-дерева другим синтасисом (без предшествующего символа "/") - c помощью относительной адресации
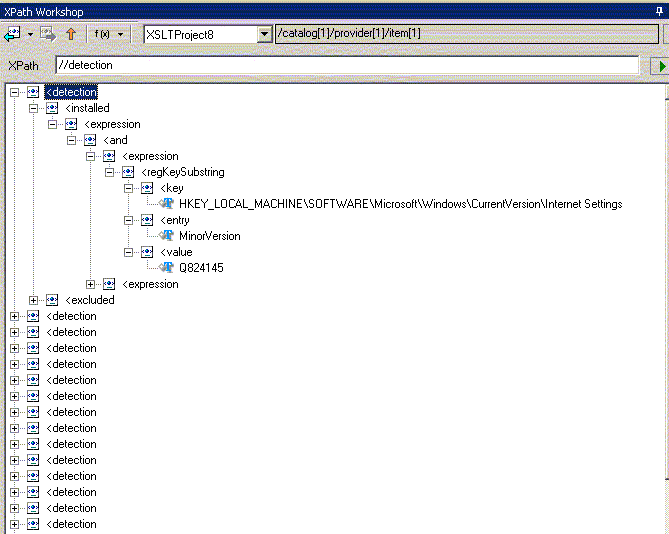
кроме того, существует специальный (сокращенный) синтаксис с двумя предшествующими "//"

позволяющий отобрать все узлы detection, независимо от местонахождения их в дереве
И наконец, в третьем правиле составления Xpath-выражений определено, что навигация по дереву осуществляется рекурсивно повторящимися шагами - STEP
при этом каждый шаг (STEP) может состоять из трех компонентов или сокращения:

сначала рассмотрим сокращение AbbreviatedStep :
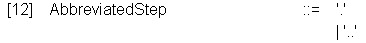
где символ "." выбирает существующий текущий узел дерева
а символ ".." - родительский узел
Теперь рассмотрим подробнее полную форму шага навигации по дереву XML-документа:
 где
гдеAxisSpecifier - называется осью навигации
NodeTest - называется тестом узла
Predicate - называется дополнительным условием отбора узлов
В свою очередь, ось навигации AxisSpecifier может состоять из сокращения AbbreviatedAxisSpecifier, и в этом случае отбираются все атрибуты узла (которые можно уточнить с помощью NodeTest и Predicate)
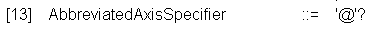
пример для навигации относительно текущего узла
абсолютная адресация

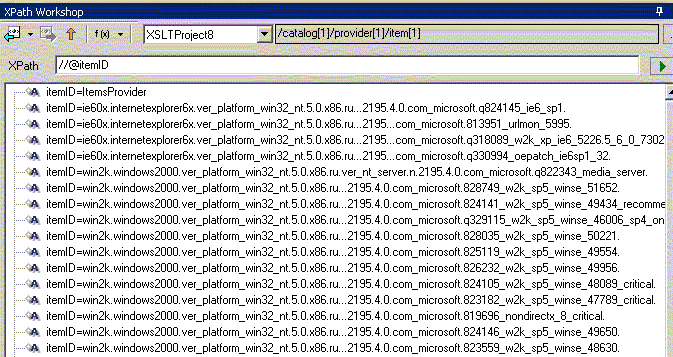
сокращенная адресация - отбор всех атрибутов itemID во всем документе
еще раз абсолютная адресация с подьемом к корню дерева

в полной форме AxisSpecifier состоит из одной из 13 осей навигации AxisName и символов "::"
 где
где| ancestor:: | содержат все родительские узлы вплоть до корня дерева |
| ancestor-or-self:: | содержат все родительские узлы вплоть до корня дерева включая текущий узел |
| attribute:: | содержит только атрибуты (текущий узел должен быть элементом) |
| child:: | содержит все прямые дочерние узлы без атрибутов и пространств имен |
| descendant:: | содержит все дочерние узлы со всеми вложенными узлами без атрибутов и пространств имен |
| descendant-or-self:: | содержит все дочерние узлы включая текущий узел со всеми вложенными узлами без атрибутов и пространств имен |
| following:: | содержит все узлы, следующие за текущим в порядке просмотра дерева. Не содержит дочерних узлов текущего, пространств имен и атрибутов |
| following-sibling:: | содержит все узлы, следующие за текущим в порядке просмотра дерева (но на том же уровне вложения от корня). Не содержит дочерних узлов текущего, пространств имен и атрибутов |
| namespace:: | содержит узлы пространств имен документа |
| parent:: | содержит один родительский узел |
| preceding:: | содержит все узлы, предшествующие текущиму в порядке просмотра дерева. Не содержит дочерних узлов текущего, пространств имен и атрибутов |
| preceding-sibling:: | содержит все узлы, предшествуюшие текущиму в порядке просмотра дерева (но на том же уровне вложения от корня). Не содержит дочерних узлов текущего, пространств имен и атрибутов |
| self:: | содержит только текущий узел |
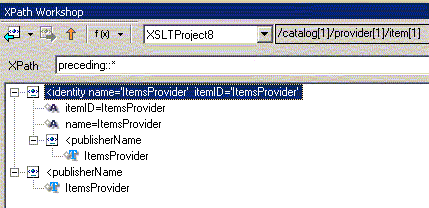
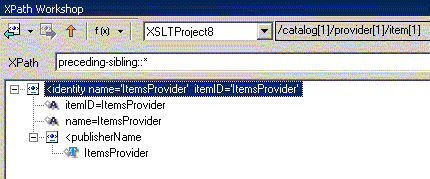
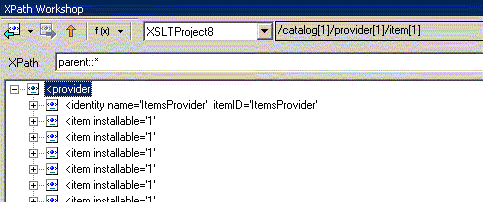
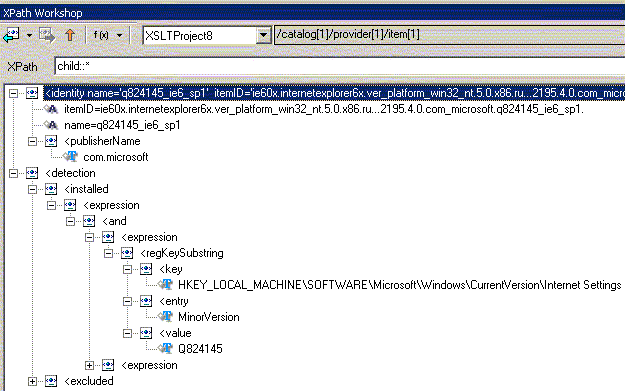
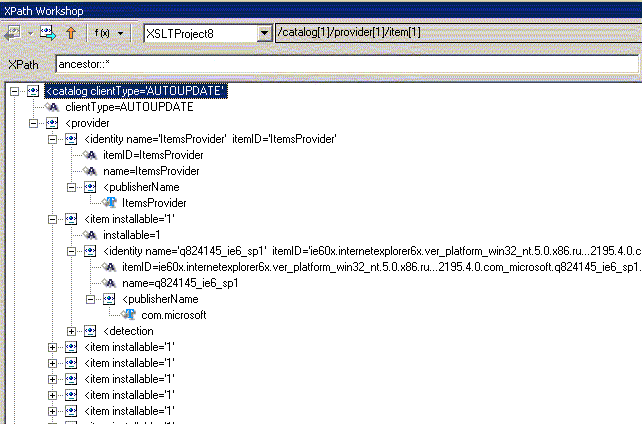
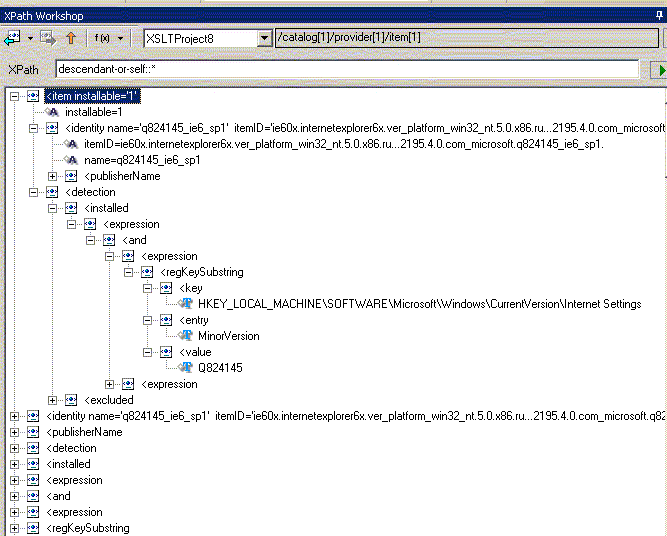
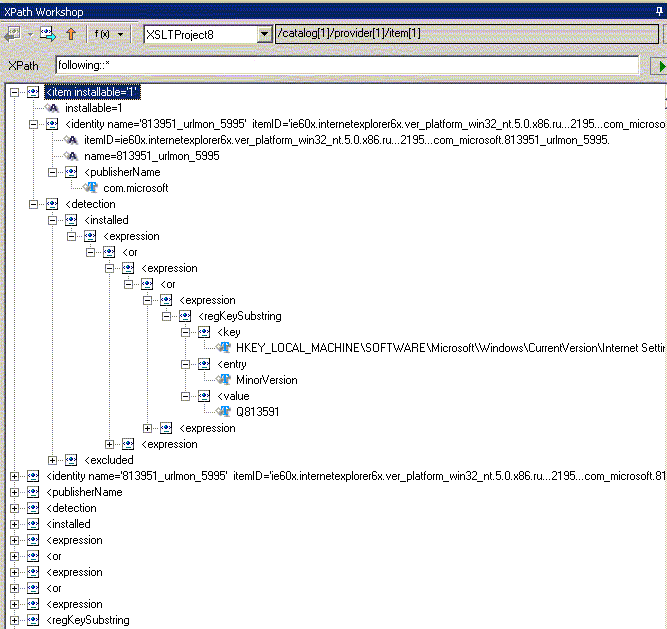
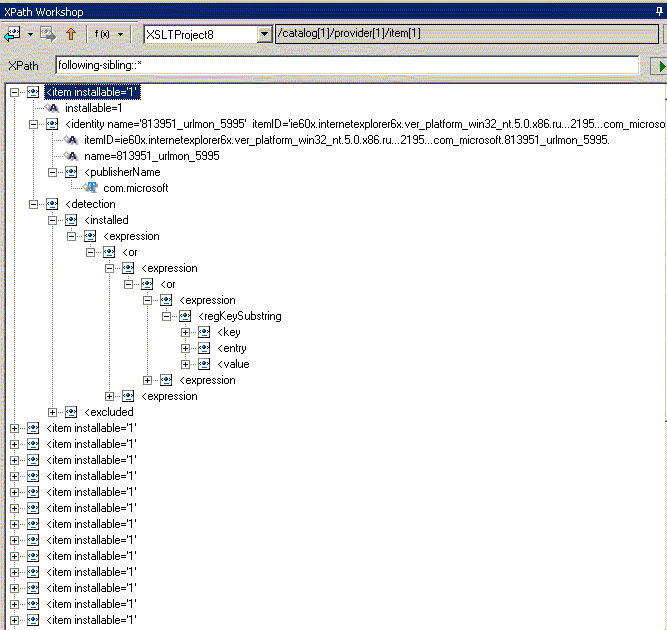
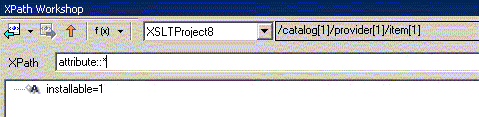
Теперь поговорим о второй части шага выборки - NodeTest (вместо которой в вышеприведенных мы в примерах использовали "*"), которая позволяет отобрать узлы различных типов, узлы обрабатываемые разными приложениями или узлы из различных пространств имен

где NameTest может быть "*", которая выбирает узел любого типа по выбранному направлению навигации, как в вышеприведенных примерах
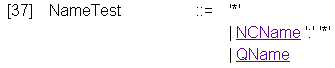
где NCName и Qname - позволяют отбирать узлы только из заданного пространства имен
например, xsl:* выберет все узлы из пространства имен с префиксом xsl
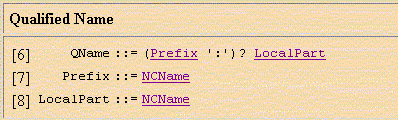
(подробнее про пространства имен XML-документов (полные QName, локальные LocalPart, умалчиваемые, префиксы Prefix и пр) смотри на http://www.w3.org/TR/REC-xml-names/)

Другой вариант NameTest - NodeType() - представляет собой один из четырех вариантов
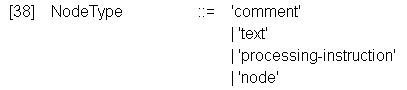
причем 'processing-instruction' может иметь в скобках текстовое выражение
| node() | выбирает любой узел по выбранной оси, как и "*" |
| comment() | комментарии |
| text() | выполняется для любого текстового узла |
| processing-instruction("имя_приложения") | отбирает узлы обрабатываемые приложением имя_приложения |
где имя_приложения задается в XML-документе в виде <?мое_приложение любые_параметры_моего_приложения?>

подробнее смотри в описании синтаксиса XML - http://www.w3.org/TR/xml11/
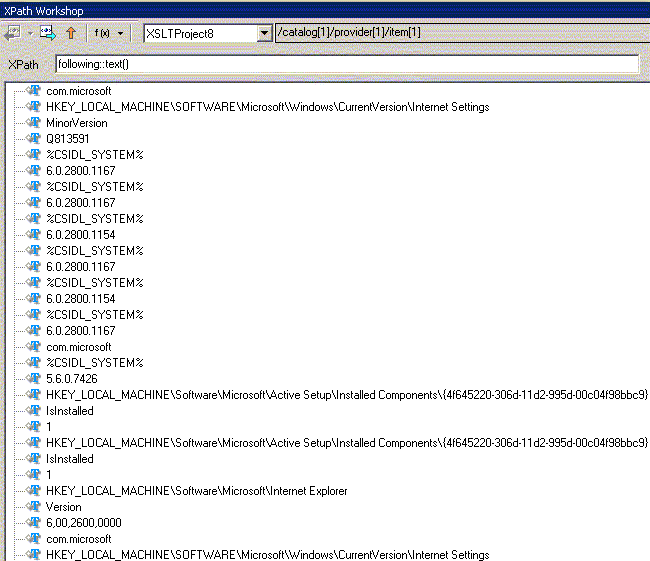
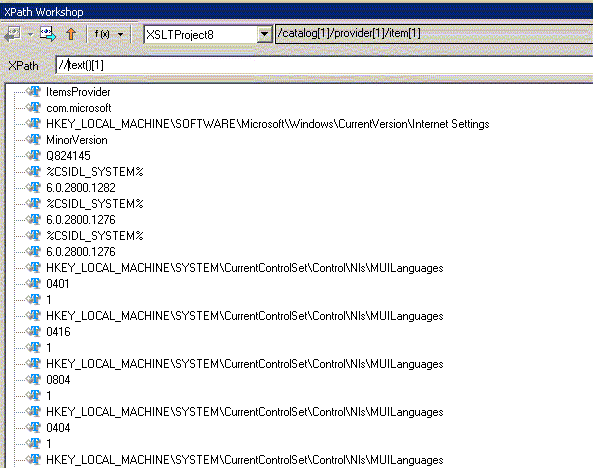
таким образом, отобрать тексты в узлах, которые предстоит просмотреть после текущего узла, можно так:
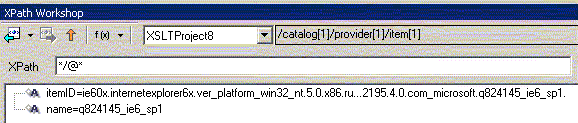
а так мы выбрали конкретное текстовое значение узла
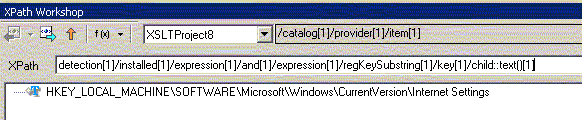
все текстовые значения документа отберутся так
И наконец, последняя, третья часть шага выборки - Predikate - это вполне обычное выражение, заданное в квадратных скобках,
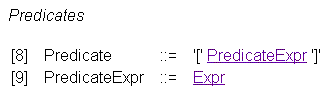
построенное на основе выражений:

1.отношений сравнения
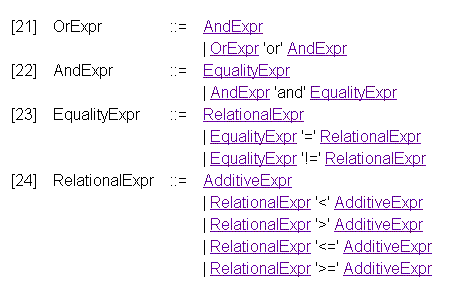
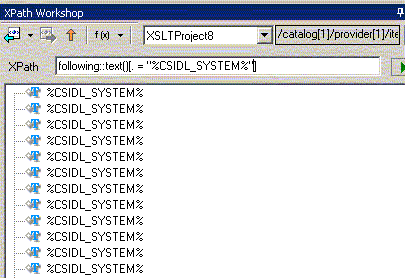
2.ссылок на переменные, определенные в XSLT (с предшествующим символом "$")

3.Номеров узлов в порядке просмотра
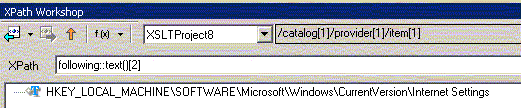
4.Вызовов функций

Стандарт Xpath определяет следующие 27 функций:
| 1.Node Set Functions | ||
| number last() | ||
| number position() | ||
| number count(node-set) | ||
| node-set id(object) | ||
| string local-name(node-set?) | ||
| string namespace-uri(node-set?) | ||
| string name(node-set?) | ||
| 2.String Functions | ||
| string string(object?) | ||
| string concat(string, string, string*) | ||
| boolean starts-with(string, string) | ||
| boolean contains(string, string) | ||
| string substring-before(string, string) | ||
| string substring-after(string, string) | ||
| string substring(string, number, number?) | ||
| number string-length(string?) | ||
| string normalize-space(string?) | ||
| string translate(string, string, string) | ||
| 3.Boolean Functions | ||
| boolean boolean(object) | ||
| boolean not(boolean) | ||
| boolean true() | ||
| boolean false() | ||
| boolean lang(string) | ||
| 4.Number Functions | ||
| number number(object?) | ||
| number sum(node-set) | ||
| number floor(number) | ||
| number ceiling(number) | ||
| number round(number) |
фактически же системы содержат большее количество функций, например Visual XSLT 2.0 содержит 38 функций (т.е.в дополнение к 27 стандартным еще 11 нестандартных функций):
current
document
element-available
format-number
function-available
generate-id
key
processing-instruction
system-property
text
unparsed-entity-uri
Теперь рассмотрим специальное подмножество языка Xpath - паттерны.
Паттерны позволяют отбирать отбирать только дочерние узлы, узлы атрибутов, все узлы ("//") или узлы, уникально идентифицированные с помощью id или key

При этом патерны перечисляются в качеcтве значения match через символ "|" (подробнее в http://www.w3.org/TR/xslt#patterns)
Патерны предназначены для использования в трех местах языка XSLT
1.Значение атрибута match элемента template:

2.Значения Count и From элемента Number:

3.Значение match элемента key:

Xml context:
Comments (
 )
)
 )
)
Link to this page:
//www.vb-net.com/convert/xslt/xpath/index.htm
|
|