WebDownloader_UltraLite - ваш личный поисковик по рунету с особыми возможностями поиска.
Эта страничка посвящена одной из моих платных программ - WebDownloader_UltraLite. Несмотря на то, что программа платная, отдельные ее компоненты представлены у меня на сайте в виде OpenSource - Этюды на ASP2. Обращение к Whois-сервису.
Мне не хотелось бы тут дублировать описание, входящее в комплект программы - его вы увидите, сгрузив и установив программу. Здесь я остановлюсь на целях написания этой программы и данных, которые она поможет собрать из интернета (пример собранных данных - WebDownload).
Сразу замечу, что в комплектацию UltraLite не включены средства построния отчетов, поэтому отчеты в этой комплектации вам придется строить не в мощной диалоговой оболочке, входящей в состав более дорогих комплектаций, а пользуясь обычными микрософтовскими прогами. Иными словами, эта версия рассчитана на тех людей, которые понимают что такое язык SQL и способны самостоятельно составить требуемый вам запрос к базе.
Для простых отчетов в Excel вы должны скопировать таблицу из MSSMS (оболочки-клиента, входящего в состав SQL2008) и вставить эти данные в Excel. Для более сложных отчетов вы можете вводить запросы не в MSSMS, а непосредственно в Excel, воспользовавшись советами на вот этой моей страничке - Избавляемся от Microsoft Reporting Services.
WebDownloader собирает из рунета данные, подобно поисковой машине Яндекс или Google. И позволяет делать запросы к собранным данным и получать отчеты. В чем-то он функционально более убогий, чем поисковая машина Яндекс, но в чем-то он позволяет делать фантастические для стандартных поисковиков запросы. В чем именно я произвел усечение фунциональных возможностей стандартных поисковиков, а в чем расширил их возможности - и как пользоваться этой программой - вы поймете из следующего описания.
1.
WebDownloader_UltraLite начинает работу со скачки Yandex и Mail-каталогов (другие версии работают иначе, например начинают с Sape.ru). В этих каталогах содержится примерно 15 тысяч страниц, которые должны быть далее распарсены и найдены первые четыреста тысяч сайтов, упомянутых в каталогах.
Как вы понимаете, эти первые четыреста тысяч сайтов (особенно с высоким рейтингом) живут обычно именно за счет того, что торгуют ссылками на другие сайты. Ссылками, размещенными на своих страницах. Те основной массив сайтов рунета можно поднять, только скачав эти первые четыреста тысяч сайтов, распарсив их, найдя в них ссылки на следующие сайты. Скачав следующую партию сайтов, распарсив их и найдя в них ссылки на следующие сайты. И так далее. Вот собственно это и делает WebDownloader_UltraLite.
Итак, самый первый этап работы программы - скачать каталоги - это делается в меню Catalog.
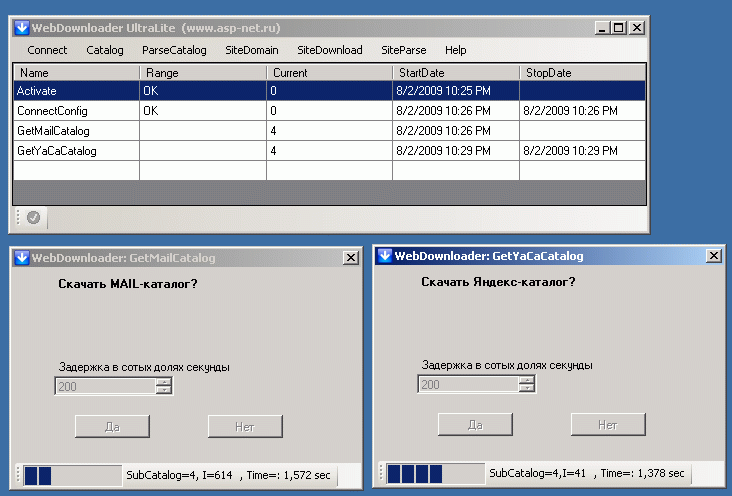
Через несколько минут вы получите в базе страницы каталогов:
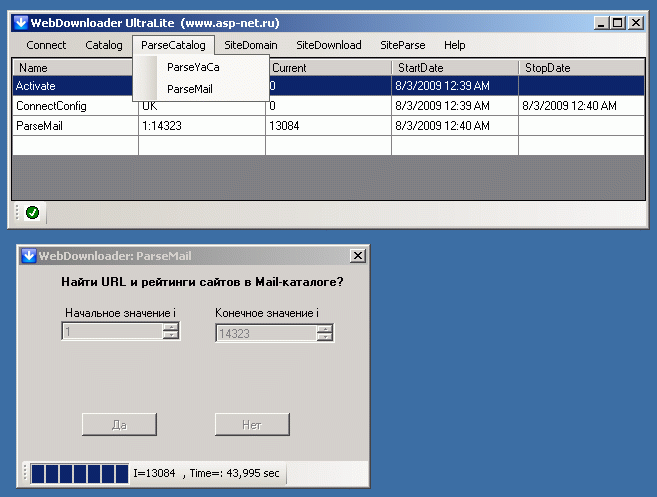
Теперь выбираем пункт меню ParseCatalog, выполняем парсинг этих страниц и выделяем из этих 14 тыс 343 страниц каталогов примерно полмиллиона сайтов, упомянутых в них.
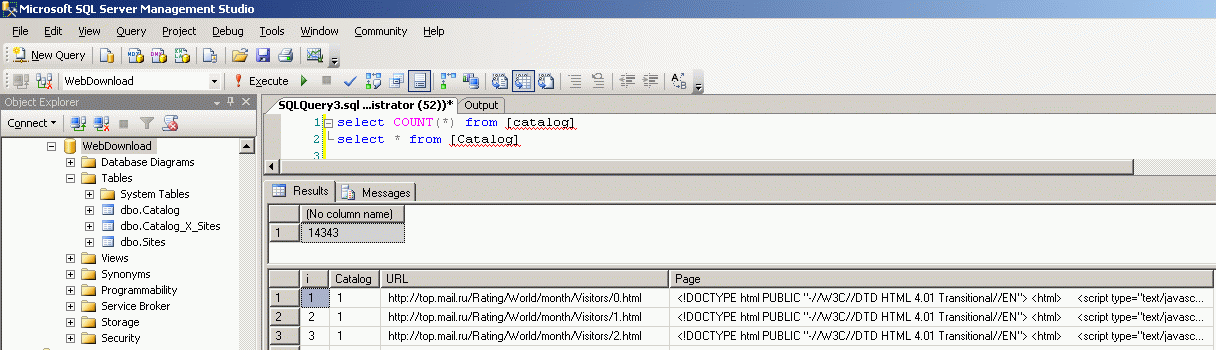
Это довольно быстрая процедура, обычно занимающая часов пять. В результате мы получаем наименования собственно первых (примерно) полумиллиона сайтов рунета, с которых начнется собственно поиск сайтов рунета - по которым будет проводится анализ.
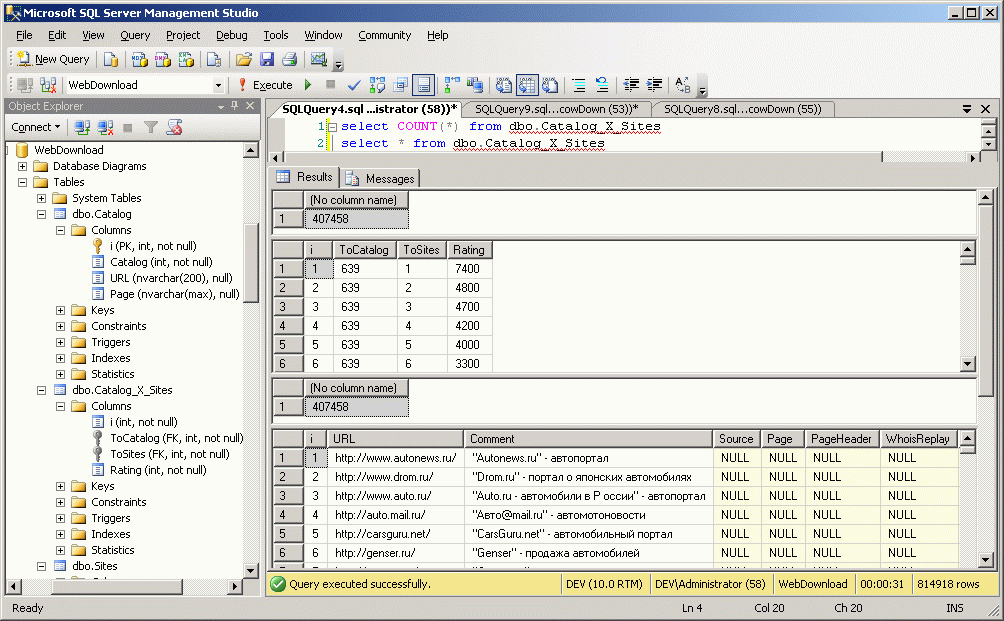
Размер базы составляет после выполнения этой операции примерно 1,5 гигабайта, что позволяет использовать SQL Express. А вот дальнейшие операции могут увеличить размер базы уже до 100 гигиабайт и более. Поскольку бесплатный SQL Express поддерживает базы размером только до 4 Гигабайт, то вам придется решить вопрос с SQL 2008 Developer Edition - которые поддерживает любые размеры базы. Как его решать - вы наверное знаете сами, но его можно купить - он стоит всего $50.
После выполнения самого первого шага вы имеете уже первые 1500 мегабайт данных, по которым можете получить первые отчеты. Пока такой отчет может быть только - рейтинг посещаемости этих первых полумиллиона сайтов рунета.
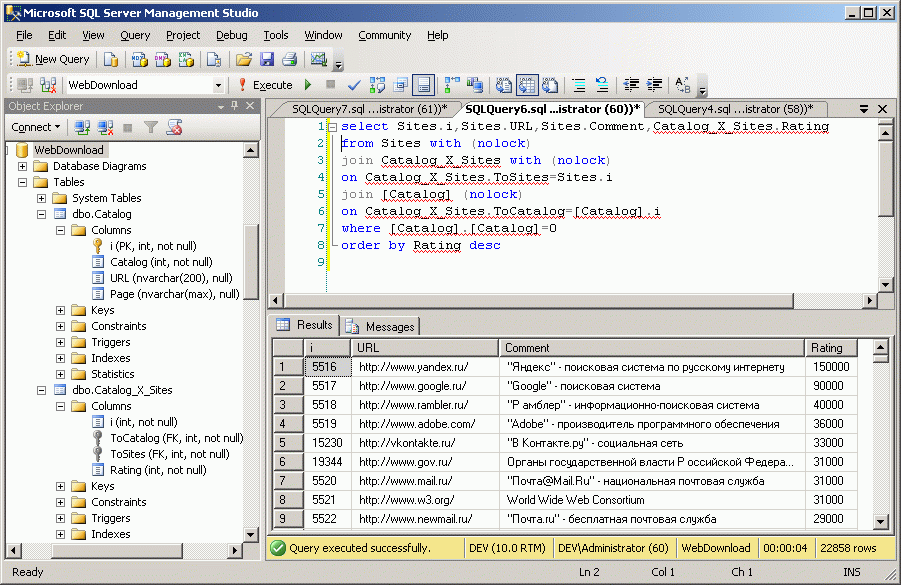
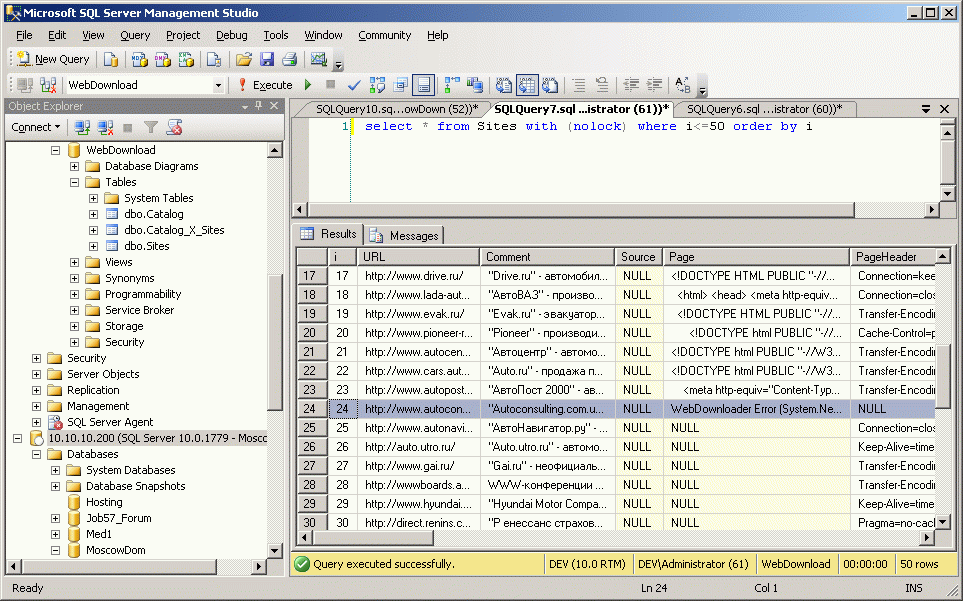
Здесь вы видите результат простейшего запроса к базе по рейтингам Яндекса, причем это сквозной запрос (вне зависимости от тематики):
1: select Sites.i,Sites.URL,Sites.Comment,Catalog_X_Sites.Rating
2: from Sites with (nolock)
3: join Catalog_X_Sites with (nolock)
4: on Catalog_X_Sites.ToSites=Sites.i
5: join [Catalog] (nolock)
6: on Catalog_X_Sites.ToCatalog=[Catalog].i
7: where [Catalog].[Catalog]=0
8: order by Rating desc
Для того чтобы сделать такой запрос по Mail-каталогу - надо в седьмой строке указать 1 (номер Mail-каталога). Для того чтобы сделать запрос по конкретной тематике - надо привязаться к тематике в таблие каталогов. Например вот запрос по рейтингам Mail-каталога по тематике Бизнес:
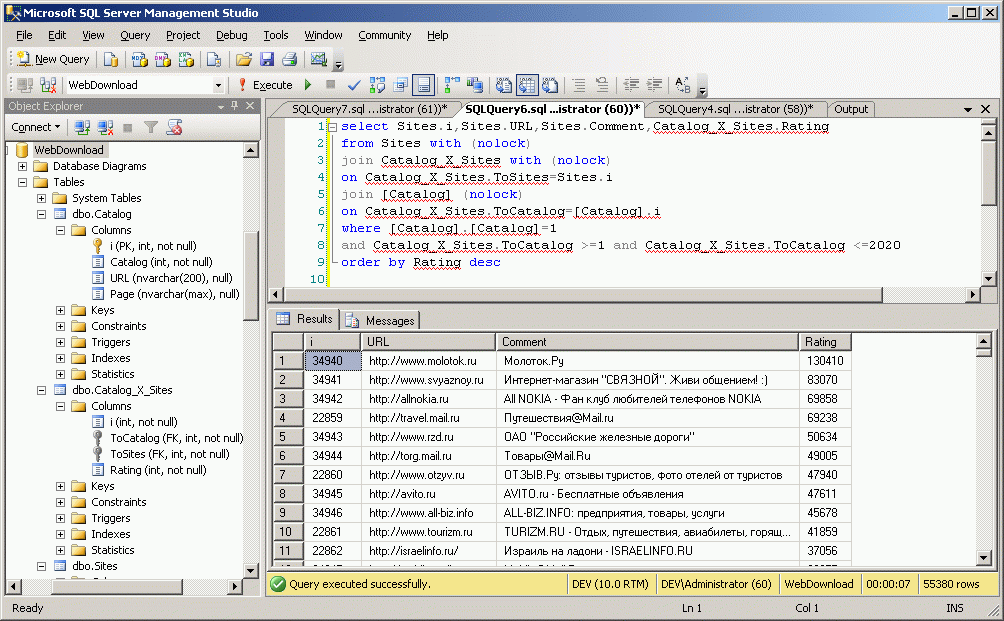
Для того, чтобы в этом запросе:
1: select Sites.i,Sites.URL,Sites.Comment,Catalog_X_Sites.Rating
2: from Sites with (nolock)
3: join Catalog_X_Sites with (nolock)
4: on Catalog_X_Sites.ToSites=Sites.i
5: join [Catalog] (nolock)
6: on Catalog_X_Sites.ToCatalog=[Catalog].i
7: where [Catalog].[Catalog]=1
8: and Catalog_X_Sites.ToCatalog >=1 and Catalog_X_Sites.ToCatalog <=2020
9: order by Rating desc
понять, где кончается один раздел, например Бизнес, а начинается следующий (например Интернет) - это число 2020 в восьмой строке - надо посмотреть таблицу рейтингов, которые каталоги дают сайтам. Рейтинг падает по мере парсинга страниц каталогов с меньшим и меньшим рейтингом, потом вдруг сразу становится большим - это и означает, что парсер перешел к парсингу следующего раздела каталогов:
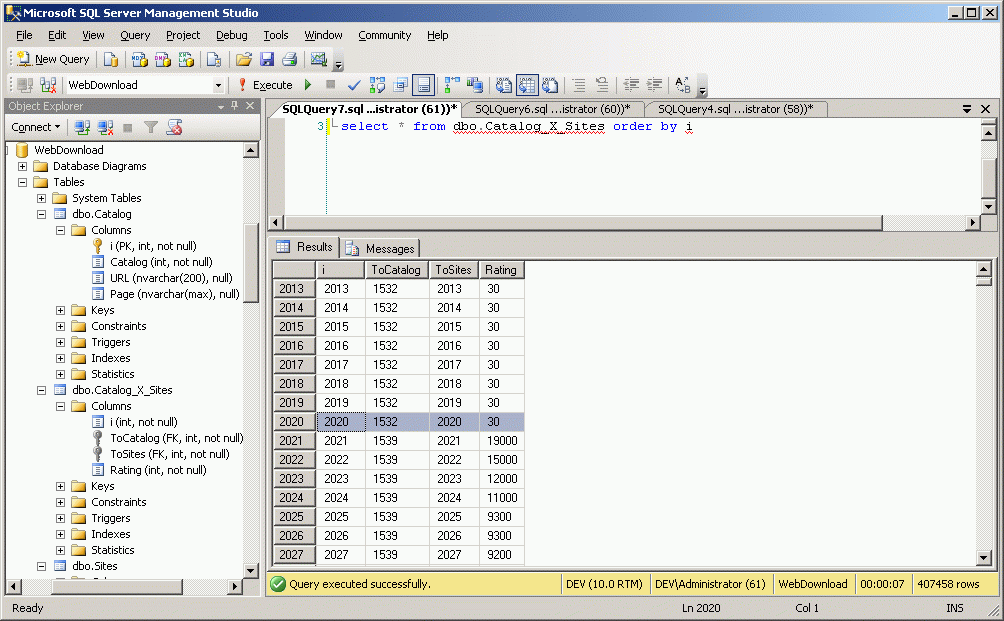
Итак, надеюсь рейтинги первых четыреста тысяч сайтов, упомянутых в указанных двух каталогах - вы поняли как получить. Но в состав WebDownloader_UltraLite включена еще одна программа - которая позволяет скачивать произвольные пейджинговые каталоги, устроенные аналогично Яндекс или Мail. В этом случае вы должны просто обозвать такой каталог другим номером, например 3,4 и так далее. И работать с ними аналогично.
WebDownloader_UltraLite скачает для вас произвольный каталог, но проблема в том, что изначально незвестно какой именно вы каталог сайтов решите скачать, поэтому текстовый парсер какого-то иного каталога (кроме Mail и Яндекс) вам или придется написать самостоятельно или заказать по реквизитам, которые вы видите на сайте //www.vb-net.com/.
Итак, надеюсь, с каталогами и парсингом из них сайтов и рейтингов все достаточно ясно - поэтому пойдем дальше по логике работы WebDownloader.
2.
Как вы понимаете, эти первые четыреста тысяч сайтов (особенно с высоким рейтингом) живут обычно именно за счет того, что торгуют ссылками на другие сайты. Ссылками, размещенными на своих страницах. Те основной массив сайтов рунета можно поднять, только скачав эти первые четыреста тысяч сайтов, распарсив их, найдя в них ссылки на следующие сайты. Скачав следующую партию сайтов, распарсив их и найдя в них ссылки на следующие сайты. И так далее. Вот собственно это и делает WebDownloader_UltraLite.
WebDownloader умеет также определять владельца домена. это мы и сделаем для наших первых (полученных из каталогов) четыреста тысяч доменов. Это длительная процедура. Запускать ее в многопоточном режиме с одного айпишника нельзя - рунетовский сервис Whois вас забанит. Параллельная работа возможна только из локалки, у которой много внешних айпишников. Однако эту операцию можно запустить в другом потоке относительно скачки или парсинга скачанных страниц.
Делается операция определения владельца доменов в два этапа - CheckDomainName и GetDomainInfo. Первая операция выделяет в базе те сайты, по которым будет проходить вторая операция. А именно определит что сайт является рунетовским (те обращаться за информацией мы будем именно в рунетовский Whois-сервис) и выделит из общего URL доменное имя для запроса к Whois-сервису. Это быстрая операция проходящая минут за 10:
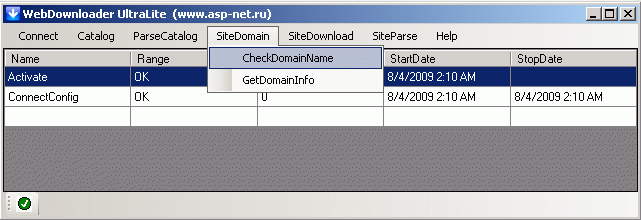
Если посмотреть данные, то после выполнения этой операции в данных окажутся заполненными поля Domain, Is_Ru, Is_Subdomain.
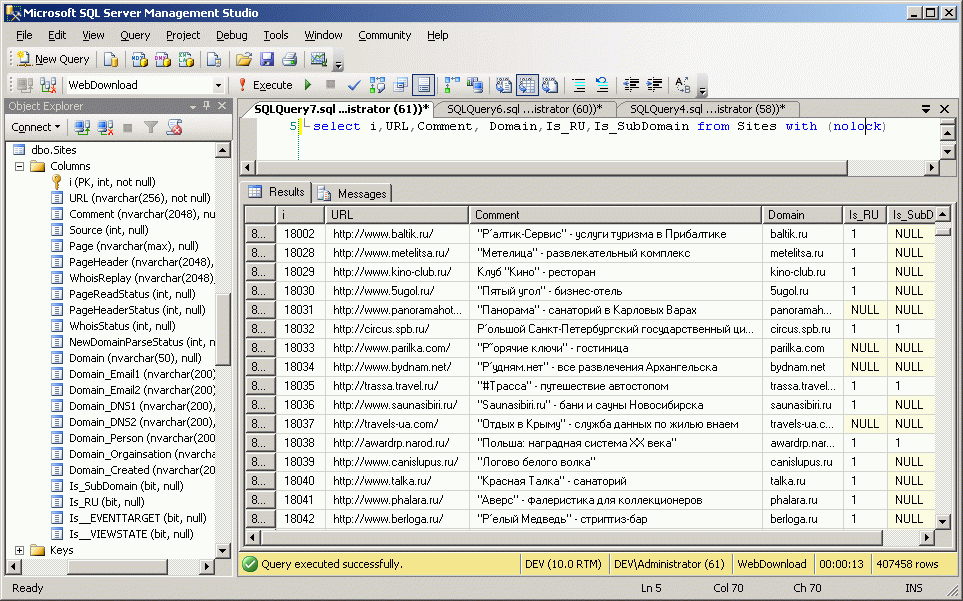
Далее надо собственно запросить рунетовский сервис о владельце домена GetDomainInfo. Это медленная операция, которая занимает более недели даже для полумиллиона сайтов. И по некоторым сайтам владелец все равно будет отсутствовать.
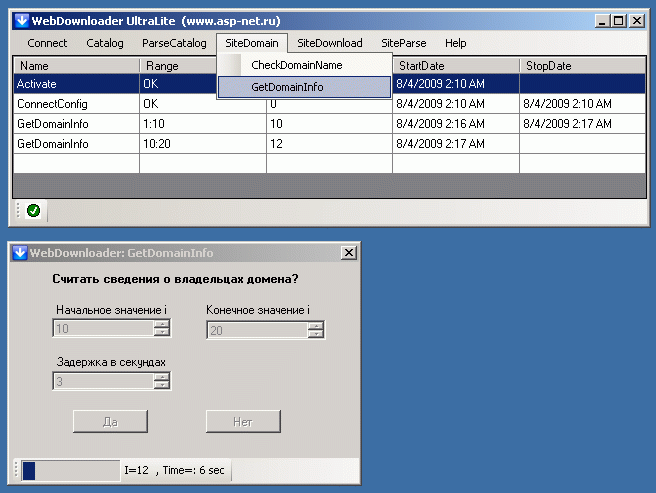
В базу сохраняется весь ответ рунетовского сервиса
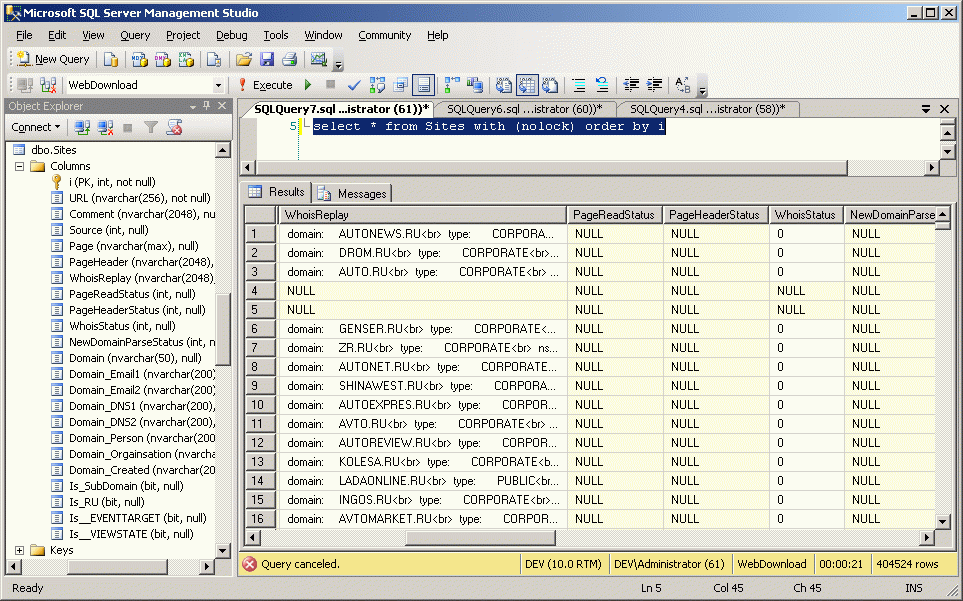
однако по колонкам WebDownloader парсит только самую важную информацию.
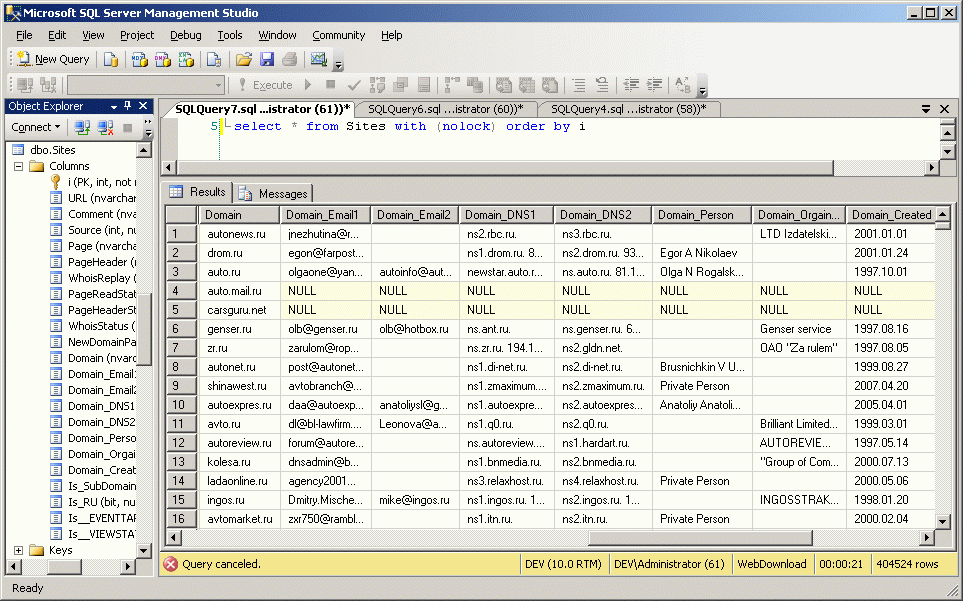
По этой информации вы можете уже выпустить многие отчеты - например год регистрации домена. Это даст вам косвенные сведения о надежности сайта. Ибо в рунете сайты живут редко более двух-трех лет. Если домен существует лет десять - значит за этим сайтом стоит серьезный устойчивый бизнес, который представляет этот сайт.
Для получения простейшего отчета о количестве доменов, созданных в конкретный год - делаем вот такой простейший запрос:
1: select
2: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1996%') as '1996',
3: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1997%') as '1997',
4: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1998%') as '1998',
5: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1999%') as '1999',
6: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2000%') as '2000',
7: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2001%') as '2001',
8: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2002%') as '2002',
9: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2003%') as '2003',
10: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2004%') as '2004',
11: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2005%') as '2005',
12: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2006%') as '2006',
13: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2007%') as '2007',
14: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2008%') as '2008',
15: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2009%') as '2009'
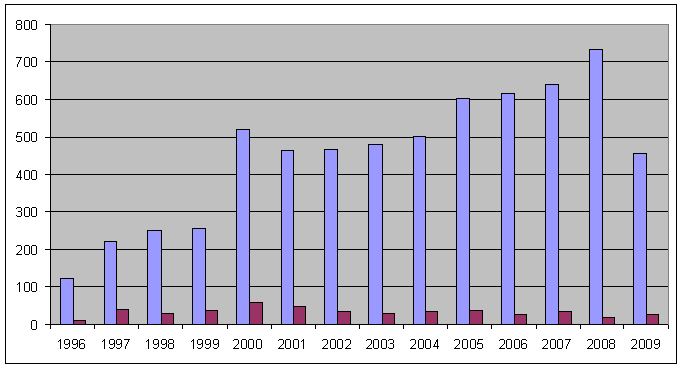
Получаем вот такой результат:
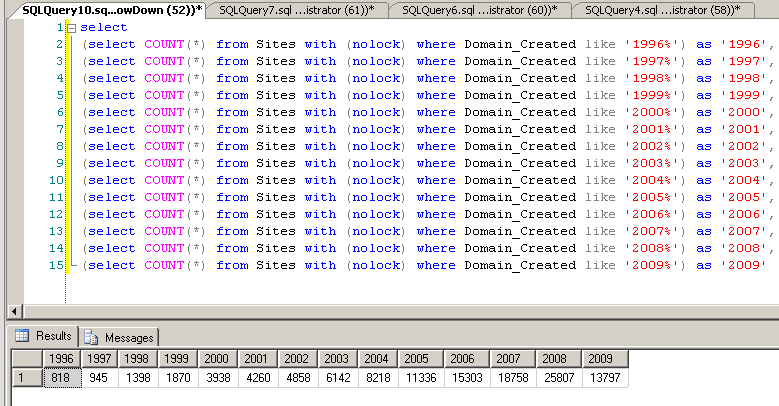
Затем делаем несколько волшебных щелчков мышкой в Excel и получаем эту табличку в виде диаграммы. Как вы понимате, 2009-й год на момент запроса еще просто не закончился. Поэтому количество созданных доменов в 2009-м году меньше чем в 2008-м.
3.
WebDownloader умеет скачивать заданные странички сайта полностью (чтобы ее парсить и искать в ней ссылки на другие сайты) или частично - только хеадер сайта - (чтобы определить технологию сайта - PHP/ASP/Windows/Unix и прочее).
Последующие шаги WebDownloader уже более длительные. Собственно скачивание может занять неделю или месяц - в зависимости от того, как глубоко вы рассчитываете углубится в рунет. Учтите также, что чем больше база - тем медленнее все работает.
WebDownloader - многопоточная программа - все операции скачки она может выполнять во много потоков - например сайты с порядковым номером в базе 1-100,000 качаются в первом потоке, 100,000-200,000 во втором потоке, 200,000-300,000 в третьем потоке, 300,000-400,000 в четвертом, 400,000-500,000 в пятом. И все это работает стабильно, без сбоев в течении, скажем, месяца. При программировании я уделял внимание именно стабильности этого движка. Чтобы он мог работать четко, без сбоев, без утечек памяти - неделями и месяцами без перезапуска, обрабатывая все кратковременные разрывы связи в локальной сети.
А вот низкоуровневые функциональные возможности собственно движка скачивания разные - в зависимости от комплектации WebDownloader. В комплектации UltraLite используется стандартный микрософтовский движок. Но микрософтоские ребята туповаты и в основном загружены своей шизоидеей: как сорвать куш побольше - поработав поменьше. Поэтому и движок у них получился гниловатый.
Взамен их движка я написал на сокетах свой собственный низкоуровневый движок. Он входит в состав более дорогой комплектации WebDownloader и позволяет то, что и не снилось микрософту. В качестве только одного небольшого примера - например вы наберете //www.vb-net.com/. Это в приниципе запрос на просмотр корневого каталога моего сайта. В нем, конечно, будет отказано Web-сервером. И микрософтовский движок дальше не идет. С их точки зрения алгоритм завершен совершенно катастрофическим отказом Web-серевера выполнять это запрещенный запрос. Однако, если введете этот адрес в браузер - то вы увидите титульную страничку моего сайта. Потому что браузер идет дальше после получения этой катастрофической ошибки. Но программный движок не идет так далеко, как браузер, а считает алгоритм обращения к Web-серверу полностью завершенным (с ошибкой). Таким образом множество сайтов не может быть скачано стандартным микрософтовским движком, а может быть скачано только моим собственным (более интеллектуальным) движком. Я привел только одну ситуацию для примера, а таких ситуаций при скачке встречается много.
Поэтому вы можете приобрести WebDownloader с микрософтовским движком скачки, или с моим собственным (дороже). Обращаю ваше внимание, что вы можете приобрести и готовую сформированную базу, которая будет уже несколько устаревшей - однако съэкономит вам время на скачку.
Запускается скачка только заголовков сайтов - в пункте меню GetSiteHeader:
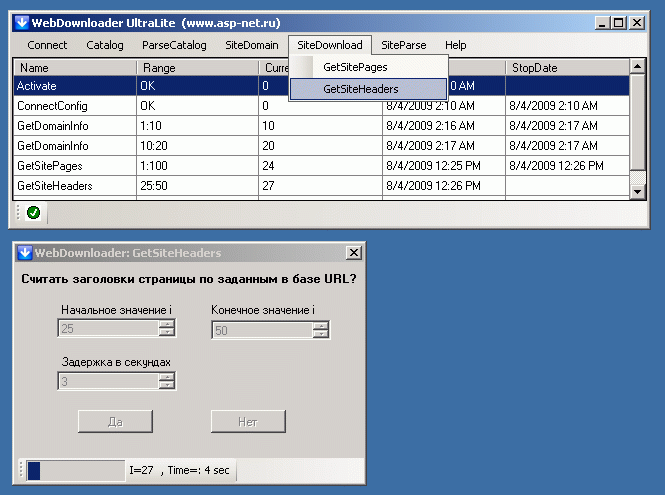
А скачка полных страниц сайтов - пунктом GetSitePages:

После скачивания у вас в базе появятся либо скачанные полностью странички (на рисунке до 24-й), либо только заголовки станичек (после 25-й), либо сообщения об ошиках (как в 24-й строке).
Даже по заголовкам вы можете выпустить множество отчетов, которые даже невозможно себе представить в стандартных поисковиках. Например все Web-сервера IIS по умолчанию имеют тип выпускаемого документа ASP.NET. Это конечно же не значит, что сайт сделан именно на ASP.NET, ибо в большинстве случаев под IIS запускают PHP и Apache, но это совершенно определенно указывает на сервер IIS. В принципе, этот параметр
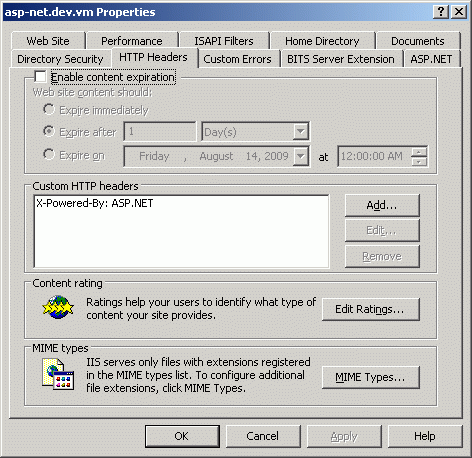
можно и убрать, но я еще не встречал такого прецедента и не могу себе представить для чего именно это необходимо делать. Следовательно, отловив этот параметр в заголовках - мы совершенно определенно увидим использование IIS. для этого введем вот такой простейший запрос, смысл которого в том, что мы легко увидим среди случайно отобранных 23,719 заголовков - какие именно Web-сервера работают под IIS, а какие под Apache и иными серверами:
1: select
2: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1996%' and not (PageHeader is null)) as '1996',
3: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1997%' and not (PageHeader is null)) as '1997',
4: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1998%' and not (PageHeader is null)) as '1998',
5: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1999%' and not (PageHeader is null)) as '1999',
6: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2000%' and not (PageHeader is null)) as '2000',
7: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2001%' and not (PageHeader is null)) as '2001',
8: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2002%' and not (PageHeader is null)) as '2002',
9: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2003%' and not (PageHeader is null)) as '2003',
10: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2004%' and not (PageHeader is null)) as '2004',
11: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2005%' and not (PageHeader is null)) as '2005',
12: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2006%' and not (PageHeader is null)) as '2006',
13: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2007%' and not (PageHeader is null)) as '2007',
14: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2008%' and not (PageHeader is null)) as '2008',
15: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2009%' and not (PageHeader is null)) as '2009'
16: union all
17: select
18: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1996%' and PageHeader not like '%ASP.NET%'),
19: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1997%' and PageHeader not like '%ASP.NET%'),
20: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1998%' and PageHeader not like '%ASP.NET%'),
21: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1999%' and PageHeader not like '%ASP.NET%'),
22: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2000%' and PageHeader not like '%ASP.NET%'),
23: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2001%' and PageHeader not like '%ASP.NET%'),
24: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2002%' and PageHeader not like '%ASP.NET%'),
25: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2003%' and PageHeader not like '%ASP.NET%'),
26: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2004%' and PageHeader not like '%ASP.NET%'),
27: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2005%' and PageHeader not like '%ASP.NET%'),
28: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2006%' and PageHeader not like '%ASP.NET%'),
29: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2007%' and PageHeader not like '%ASP.NET%'),
30: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2008%' and PageHeader not like '%ASP.NET%'),
31: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2009%' and PageHeader not like '%ASP.NET%')
32: union all
33: select
34: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1996%' and PageHeader like '%ASP.NET%'),
35: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1997%' and PageHeader like '%ASP.NET%'),
36: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1998%' and PageHeader like '%ASP.NET%'),
37: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1999%' and PageHeader like '%ASP.NET%'),
38: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2000%' and PageHeader like '%ASP.NET%'),
39: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2001%' and PageHeader like '%ASP.NET%'),
40: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2002%' and PageHeader like '%ASP.NET%'),
41: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2003%' and PageHeader like '%ASP.NET%'),
42: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2004%' and PageHeader like '%ASP.NET%'),
43: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2005%' and PageHeader like '%ASP.NET%'),
44: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2006%' and PageHeader like '%ASP.NET%'),
45: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2007%' and PageHeader like '%ASP.NET%'),
46: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2008%' and PageHeader like '%ASP.NET%'),
47: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2009%' and PageHeader like '%ASP.NET%')
На результат, этого запроса:

посмотрим в более удобном виде:
Как видите, результат запроса весьма любопытен. Применение серверов IIS в Web-технологиях не только чрезвычайно мало по сравнению с другими Web-серверами, но и каждый следующий год в интернете появляется все больше и больше серверов под UNIX и прочими системами и все меньше и меньше серверов под Windows (IIS).
4.
Следующий этап - распарсить скачанные полностью странички в поисках ссылок в них на другие сайты. Это пункт меню GetNewDomain. Это длительная (и вычислительно тяжелая для SQL-сервера)процедура. Одно дело добавить сайт в базу где четыреста тысяч сайтов (а надо проверить что в базе этого сайта еще нет) другое дело добавить сайт в базу с миллиардом сайтов (и надо проверить что нового добавляемого сайта еще нет среди учтеного миллиарда сайтов).
Операция поиска на странице ссылок на другие домены выполняется в последнем пункте меню WebDownloader_UltraLite - GetNewDomain:
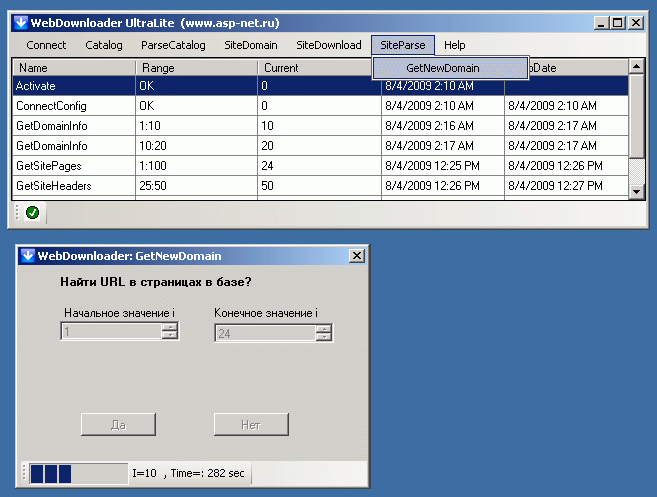
В этом случае база пополнилась новыми URL, а в поле Source появилась строка источник записи для попадания этого URL в базу.
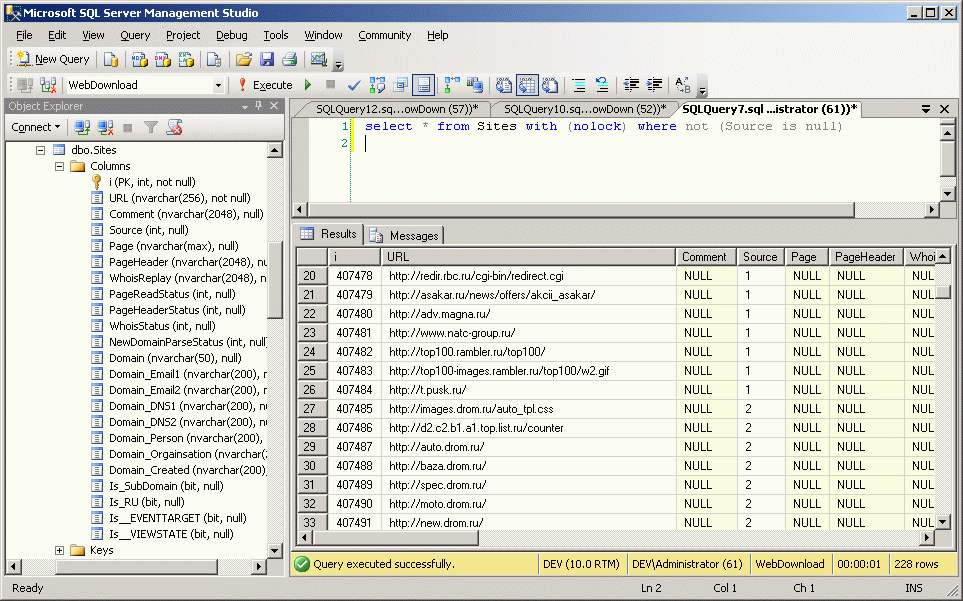
Таким образом легко отличить в запросах изначальные 400 тыс URL, которые попали в базу в результате парсинга каталогов и новые URL, которые ложатся в базу в результате парсинга уже уложенных в базу страниц.
По всем новым URL, которым пополнилась база в результате исполнения этого пункта меню - можно определить владельцев доменов и можно опять же запустить скачку страниц. Потом опять распарсить их в поисках новых ссылок и опять скачать их. И так до бесконечности. В сущности так работают все поисковые машины, только переход между пунктами меню GetSitePages и GetNewDomain в них происходит программно, без участия человека. И сайт скачивается полностью, а не только одна страничка, на которую есть ссылка и мы уверены, что в домене эта страничка точно существует. Те поисковая машина ищет не только ссылки на внешние домены (на чем сконцентрирован WebDownloader_UltraLite), а скачивает и внутренние странички в домене.
В принципе вы можете укладывать URL в базу, которые вам требуется скачать - и иными средствами. Какими-то своими собственными программами, а WebDownloader_UltraLite использовать как движок для скачки этих URL. Это возможное пользовательское расширение WebDownloader_UltraLite вашими собственными программами - так же как в случае, описанном выше. Когда WebDownloader_UltraLite может скачать произвольный пейджинговый каталог, но парсер неизвестного каталога заранее изготовить невозможно - поэтому парсер вашего произвольного каталога вы можете написать только сами. И он станет вашим личным расширением WebDownloader_UltraLite.
Теперь, после рассмотрения последнего пункта меню, думаю, становится полностью понятным назначение программы WebDownloader_UltraLite - это функционально усеченная поисковая машина Яндекс, Google или Yahoo. Усеченная в части обхода домена полностью по всем и прочим страницам внутри домена, но расширенная во многих отношениях - например в части определения владельца домена, скачки только заголовка сайта или поиска по неотображаемым полям страниц.
Естественно, вы можете в данных, скачанных WebDownloader, выполнять и обычные примитивные поисковые запросы, которые вы обычно выполняете в Яндекс или Google.
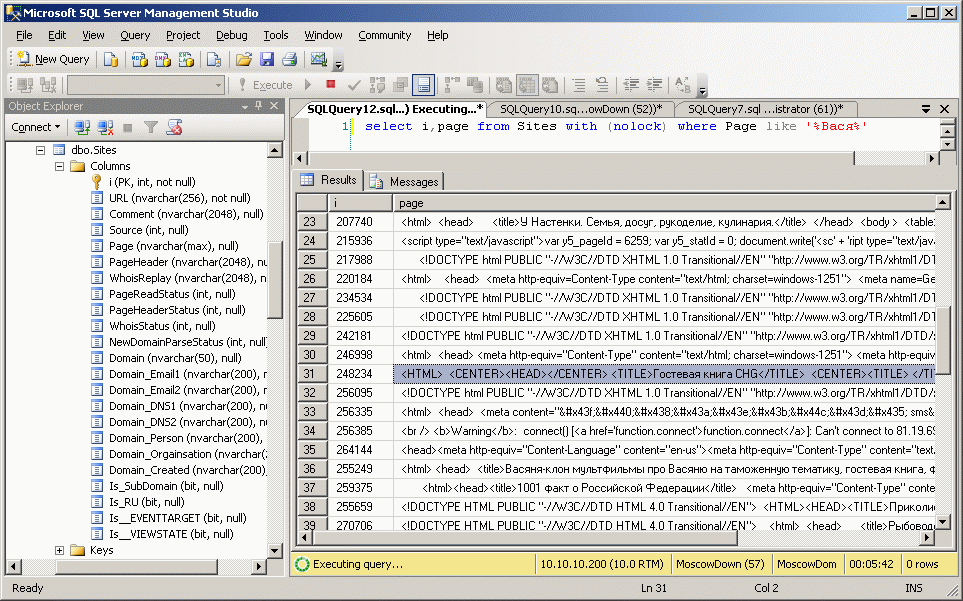
Другое дело, что поисковые машины делают еще один проход по скачанным данным - исключительно для ускорения поиска (пример такого прохода делает вот эта моя старая заброшенная программка - SiteChecker - утилита оптимизация сайта с открытым исходным текстом) - поэтому скорость таких запросов к сырым данным WebDownloader будет существенно ниже. Однако результат, аналогичный обычным поисковым машинам, как вы видите, вы получите все равно. Здесь только надо понимать, что версия WebDownloade_UltraLite обходит рунет вширь (в поисках новых и новых доменов), а не вглубь (в поисках всех страниц в домене), те в комплектацию UltraLite в пункте меню GetSiteParse входит только программа GetNewDomain не входит программа GetAllPage (которая скачивает все достижимые страницы в домене).
5.
Естественно, имея свою базу поисковой машины рунета - вы можете выполнять такие поиски и анализы, которые и не снились поисковой машине Яндекс или Google. Я уже показал вам два запроса к базе - запрос, использующий доменную информацию и запрос, использующий заголовок страницы. Теперь я покажу третий запрос, использующий скрытые поля страницы, которые не отображаются в браузере.
Итак, однажды я задал себе вопрос - какая часть всех сайтов сделана на ASP.NET (фирменной технологии Microsoft), а какая на PHP и прочих технологиях. Интерес был вполне шкурный, ибо я сам являюсь ASP.NET программистом и каждый сайт на ASP.NET - это прежде всего мой потенциальный заказчик. Как вы понимаете, такой же вопрос может например задать себе Юниксовый админ, Bitrix-конфигуратор, JAVA или PHP программист. Какие сайты в их городе работают по знакомым им технологиям? Насколько надежны эти компании, как долго работают? Как связатся с владельцами этих сайтов? Такой анализ я покажу на примере ASP.NET.
Как ASP.NET программист я точно знаю, что должно присутствовать на любой ASP.NET страничке - это должна быть переменная __VIEWSTATE (для страниц, у которых есть хоть что-нибудь кроме ссылок), и переменная __EVENTTARGET, (для настоящих страниц на ASP.NET - на которых присутствуют микросовские контролы - ну хотя бы Button). В принципе есть ухищрения, позволяющие убрать эти переменные со странички непосредственно на сервер Хранение состояния страниц на сервере, однако это чрезвычайно гиморойная практика и весьма-весьма нагружающая сервер. Те в обычном режиме ,скажем для примера, 50% процессорного времени на обработку странички перекладывается на клиента, а 50% на сервер. В таком хитром варианте, когда состояние хранится на сервере - страничка будет быстро работать и на Pentium 1, ибо на клиента перекладывается 10% нагрузки по обработке странички, а 90% нагрузки перекладывается на сервер (цифры тут достаточно условные). Однако, ведь сервер обрабытывает одновременно сотни, а может быть и тысячи страниц - а клиент всегда только одну текущую, поэтому такая техника построения сайтов требует сверх мощных серверных кластеров, скажем, гораздо дороже 100 тысяч долларов за каждый. Возможно какие-то сайты этой технологией и пользуются, однако я исхожу из того, что основная масса (не менее 99% всех сайтов на ASP.NET) - используют стандартное серверное оборудование и стандартную ASP.NET технику рендеринга странички, а значит на страничке есть __VIEWSTATE и __EVENTTARGET (если это активная страничка с контролами) и __VIEWSTATE, если это пассивная страничка на ASP.NET, в которой VS2008 используется в режиме нотепада с подсветкой (только для HTML-верстки).
Для выполнения этого анализа нам понадобится вот такой запрос (я заведомо внес в структуру базы флаги для этого запроса - свои собственные, интересующие вас флаги вы можете добавить в базу в любой момент самостоятельно командой ALTER TABLE Sites ADD MyFlag bit NULL):
1: update dbo.Sites with (ROWLOCK) set Is__VIEWSTATE=1 where not (Page is null) and Page like '%__VIEWSTATE%'
2: and ( i>=1 and i<50000)
3: go
4: update dbo.Sites with (ROWLOCK) set Is__VIEWSTATE=1 where not (Page is null) and Page like '%__VIEWSTATE%'
5: and ( i>=50000 and i<100000)
6: go
7: update dbo.Sites with (ROWLOCK) set Is__VIEWSTATE=1 where not (Page is null) and Page like '%__VIEWSTATE%'
8: and ( i>=100000 and i<150000)
9: go
10: update dbo.Sites with (ROWLOCK) set Is__VIEWSTATE=1 where not (Page is null) and Page like '%__VIEWSTATE%'
11: and ( i>=150000 and i<200000)
12: go
13: update dbo.Sites with (ROWLOCK) set Is__VIEWSTATE=1 where not (Page is null) and Page like '%__VIEWSTATE%'
14: and ( i>=200000 and i<250000)
15: go
16: update dbo.Sites with (ROWLOCK) set Is__VIEWSTATE=1 where not (Page is null) and Page like '%__VIEWSTATE%'
17: and ( i>=250000 and i<300000)
18: go
19: update dbo.Sites with (ROWLOCK) set Is__VIEWSTATE=1 where not (Page is null) and Page like '%__VIEWSTATE%'
20: and ( i>=300000 and i<350000)
21: go
22: update dbo.Sites with (ROWLOCK) set Is__VIEWSTATE=1 where not (Page is null) and Page like '%__VIEWSTATE%'
23: and ( i>=350000 and i<400000)
24: go
25: update dbo.Sites with (ROWLOCK) set Is__VIEWSTATE=1 where not (Page is null) and Page like '%__VIEWSTATE%'
26: and ( i>=400000 and i<450000)
Like - сложная процессорная задача для SQL-сервера. Он может выполнять ее несколько дней в большой базе. Поэтому тут запрос для простоты разбит на несколько секций. Аналогичный запрос прогоняется с переменной EVENTTARGET:
1: update dbo.Sites with (ROWLOCK) set Is__EVENTTARGET=1 where not (Page is null) and Page like '%__EVENTTARGET%'
2: and ( i>=1 and i<50000)
3: go
4: update dbo.Sites with (ROWLOCK) set Is__EVENTTARGET=1 where not (Page is null) and Page like '%__EVENTTARGET%'
5: and ( i>=50000 and i<100000)
6: go
7: update dbo.Sites with (ROWLOCK) set Is__EVENTTARGET=1 where not (Page is null) and Page like '%__EVENTTARGET%'
8: and ( i>=100000 and i<150000)
9: go
10: update dbo.Sites with (ROWLOCK) set Is__EVENTTARGET=1 where not (Page is null) and Page like '%__EVENTTARGET%'
11: and ( i>=150000 and i<200000)
12: go
13: update dbo.Sites with (ROWLOCK) set Is__EVENTTARGET=1 where not (Page is null) and Page like '%__EVENTTARGET%'
14: and ( i>=200000 and i<250000)
15: go
16: update dbo.Sites with (ROWLOCK) set Is__EVENTTARGET=1 where not (Page is null) and Page like '%__EVENTTARGET%'
17: and ( i>=250000 and i<300000)
18: go
19: update dbo.Sites with (ROWLOCK) set Is__EVENTTARGET=1 where not (Page is null) and Page like '%__EVENTTARGET%'
20: and ( i>=300000 and i<350000)
21: go
22: update dbo.Sites with (ROWLOCK) set Is__EVENTTARGET=1 where not (Page is null) and Page like '%__EVENTTARGET%'
23: and ( i>=350000 and i<400000)
24: go
25: update dbo.Sites with (ROWLOCK) set Is__EVENTTARGET=1 where not (Page is null) and Page like '%__EVENTTARGET%'
26: and ( i>=400000 and i<450000)
проставив в базу эти флаги, делаем по ним запрос:
1: select
2: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1996%' and not (Page is null)) as '1996',
3: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1997%' and not (Page is null)) as '1997',
4: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1998%' and not (Page is null)) as '1998',
5: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1999%' and not (Page is null)) as '1999',
6: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2000%' and not (Page is null)) as '2000',
7: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2001%' and not (Page is null)) as '2001',
8: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2002%' and not (Page is null)) as '2002',
9: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2003%' and not (Page is null)) as '2003',
10: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2004%' and not (Page is null)) as '2004',
11: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2005%' and not (Page is null)) as '2005',
12: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2006%' and not (Page is null)) as '2006',
13: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2007%' and not (Page is null)) as '2007',
14: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2008%' and not (Page is null)) as '2008',
15: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2009%' and not (Page is null)) as '2009'
16: union all
17: select
18: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1996%' and Is__VIEWSTATE=1),
19: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1997%' and Is__VIEWSTATE=1),
20: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1998%' and Is__VIEWSTATE=1),
21: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1999%' and Is__VIEWSTATE=1),
22: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2000%' and Is__VIEWSTATE=1),
23: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2001%' and Is__VIEWSTATE=1),
24: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2002%' and Is__VIEWSTATE=1),
25: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2003%' and Is__VIEWSTATE=1),
26: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2004%' and Is__VIEWSTATE=1),
27: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2005%' and Is__VIEWSTATE=1),
28: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2006%' and Is__VIEWSTATE=1),
29: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2007%' and Is__VIEWSTATE=1),
30: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2008%' and Is__VIEWSTATE=1),
31: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2009%' and Is__VIEWSTATE=1)
32: union all
33: select
34: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1996%' and Is__EVENTTARGET=1),
35: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1997%' and Is__EVENTTARGET=1),
36: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1998%' and Is__EVENTTARGET=1),
37: (select COUNT(*) from Sites with (nolock) where Domain_Created like '1999%' and Is__EVENTTARGET=1),
38: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2000%' and Is__EVENTTARGET=1),
39: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2001%' and Is__EVENTTARGET=1),
40: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2002%' and Is__EVENTTARGET=1),
41: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2003%' and Is__EVENTTARGET=1),
42: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2004%' and Is__EVENTTARGET=1),
43: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2005%' and Is__EVENTTARGET=1),
44: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2006%' and Is__EVENTTARGET=1),
45: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2007%' and Is__EVENTTARGET=1),
46: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2008%' and Is__EVENTTARGET=1),
47: (select COUNT(*) from Sites with (nolock) where Domain_Created like '2009%' and Is__EVENTTARGET=1)
В результате запроса получаем вот такой результат:

Думаю, самому богатому человеку планету Биллу Гейтсу следовало бы удавится, увидев такой результат своих усилий - те самые (почти неразличимые на диаграмме) десятые и сотые доли процента - и есть сайты на чудо-технологии ASP.NET, изобретенной Microsoft'ом.
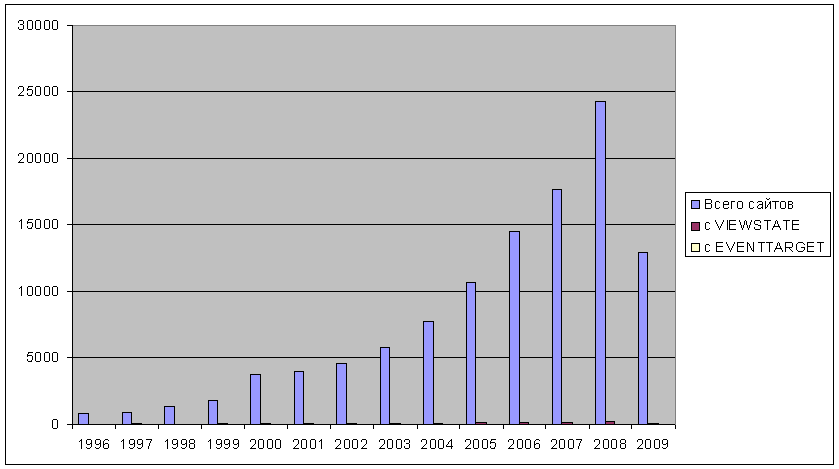
Признаться, эти результаты меня, как ASP.NET-программиста, глубоко шокировали. Я надеялся, что технология, на которой я программирую, занимает хотя бы пару твердых процентов рынка Web-приложений. Я стал искать ошибку в рассуждениях и заметил возможную недостоверность полученных данных в двух взаимно уравновешивающих моментах.
Во-первых, вероятно среди проанализированных 400 тыс сайтов есть ОЧЕНЬ крупные порталы, типа www.votpusk.ru. В таких порталах главный домен и главная страница изготовлены НЕ на ASP.NET, но существуют десятки поддоменов, изготовленных именно на ASP.NET, например video.votpusk.ru, foto.votpusk.ru, story.votpusk.ru, poputi.votpusk.ru, user.votpusk.ru, search.votpusk.ru, arenda.votpusk.ru. Поскольку в базе указан лишь корневой домен, поэтому и весь портал не считается написанным на ASP.NET.
Однако, есть и противоположный эффект. Огромное количество самых топовых ресурсов лишь внешне похожи на сайты ASP.NET, например http://ru.wikipedia.org/, однако изготовлены они не с помощью Visual Studio 2005/2008 и микрософтоского ASP.NET, а с помощью совсем иного инструмента MonoDevelop и хостятся не под ASP.NET, а под Mono.
Трудно сказать каких ситуаций среди этих исчезающе малых сотых и тысячных долей процентов на рынке Web-приложений больше - сайтов, изготовленных на бесплатном клоне ASP.NET или крупных порталов, которые стали развиваться на ASP.NET - не переделав титульную страницу своего портала. Но в обоих случаях это будут лишь небольшие отклонения от десятых долей процета, которые напрямую видны в теле страничек.
Напомню, что опубликованные здесь данные анализа произведены по вот этой базе (левая колонка).
Пожалуйста, сообщайте обо всех замеченных багах в баг-трекер программы WebDownloader_UltraLite.
Еще некоторые мои размышления о рынке Web-приложений можно посмотреть в топиках:
- Microsoft начала раcпространять PHP 5
- Знакомство с Visual Studio 2010.
- Мой первый сайт на MVC 3 Razor
- Подарки от Microsoft для ASP.NET программистов
WinDesktop context:
 )
)
|
|