Специализированные технологии обработки строк в NET.
В этом разделе я расскажу о древнейшей проблеме программирования - обработке строк. Эта одна из классических проблем программирования, наряду, скажем, с проблемой запоминания массовых единообразных данных (из чего родились системы управления данными, язык SQL и пр.), с проблемой вывода данных в удобном для человека графическом формате (из чего родились спецификации OpenGL, DirectX и др.), обработкой ошибок программ, программированием обьектов и другими такими же извечными проблемами программирования.
К сожалению даже многие составители учебных курсов по программированию не осознают того важного факта, что ВСЕ нижеперечисленные технологии являются не более чем некоторыми техниками преобразования символьных строк. Лично мне практически в каждой программе приходиться в той или иной степени работать со строками символов и поэтому мне эта тема ближе, чем, скажем, графический вывод. Я так же в той или иной степени сталкивался со всеми современными технологиями обработки строк, чем и вызвано появление этого раздела на моем сайте.
Даже самые древние языки программирования типа Algol 68 или Fortran имели набор функций для работы со строками. Обычно это самые элементарные функции выделения подстроки с некоторой позиции строки, поиска заданной подстроки в строке, конкатенации строк, преобразования цифр в строки и обратно и тому подобны элементарные функции. Самая продвинутая из простейших строчных функций - split. Естественно, такими элементарными функциями можно решить только элементарные задачи. Поэтому обработка строк разделилась на несколько специализированных технологий:
- Первая - XSLT-трансформации, применяется только для обработки строк, предварительно отформатированных тегами по правилам стандарта XML. (А ведь строки можно разбить тегами по правилам, скажем RTF-документа или HTML - но тогда XSLT-трансформации применить уже не удасться - такие строки удасться проанализировать только вторым способом.)
Это самая распространенная технология. Она применяется сейчас практически в каждой полученной вашим браузером HTML-странице (собственно, любой из браузеров и является XSLT-преобразователем). Наряду с тем, что инструментальных систем для разработки XSLT-трансформаций существуют тысячи, многие из этих систем используются более чем миллионом программистов. Более того, XSLT-транформации уже реализованы в виде специализированной микросхемы и, соотвественно, существуют специализированные аппаратные XSLT-преобразователи.
- Вторая - собственно HTTP-парсеры, предоставляющие специализированные методы преобразования HTML-строк, полученных через интернет. Практическое воплощение эта технология получила при DHTML-программировании, когда строка HTTP-документа представляется в виде обьектной модели. Лично я никогда не разбираю HTTP вот так, а использую обьектную модель HTTP в любой своей программе, в которой требуется распарсить HTTP.
- Третья. Не только все клиентские технологии - это функции преобразования строк. Все современные серверные технологии - это тоже не более чем формирование текстовой строки, передаваемой браузеру. Например, мы можем проигнорировать всю специализированную функциональность ASP2 и написать прямо внутри ASP2:
Response.ContentsType="text/html" : Response.Write ("<html>Привет</html>")
или даже для формирования HTML-cтроки подтянуть COM-обьект, скажем с библиотекой PERL и формировать на строку внутри Response.Write с помощью техники, специализированной для PERL.
- Червертая - Преобразование (отбор частей и соединение отобранных фрагментов) XML-отформатированных строк посредством запросов xPath на языке Xquery. С некоторых пор я пользуюсь этой техникой довольно часто. Этот способ преобразования строк достаточно подробно описан у меня на сайте. Со временем я дополню это описание практическими примерами использования этих запросов в своих программах. Посмотрите еще пару статей на эту тему: XQuery: язык запросов XML , Разоблачение мифов и заблуждений о XQuery.
- Пятая - Фильтрация XML-данных по XSD-схеме. Большинство соврменных программ хранит свои настройки в виде файлов XML и постоянно сверяет допустимость своих настроечных файлов по XML-схемам.
В SQL2005 предусмотрено спецхранилище для манипулирования XML-схемами. Это позволяет типизированные XML-данные, хранимые в SQL-поле, проверять на соответствие схеме. Простейший способ получить XSD-схему - указать XMLSCHEMA при отборе из SQL-сервера по FOR XML. При этом, благодаря импортированию пространства имен SQL2005, получается гораздо более качественная схема, чем можно составить без этого пространства имен.
- Шестая - анализ и обработка строк с помощью регулярных выражений. Применяется чрезвычайно широко для анализа произвольных (не отформатированных тегами) строк и является основой многих языков, например Perl.
Регулярные выражения также часто применяется и при программировании на VbScript и VB6. Более того, даже сама библиотека VBSCRIPT.DLL лишь на одну треть состоит собственно из обработчика языка VBSCRIPT, вторая часть VBSCRIPT.DLL/2 содержит обработчик MS Regular Expression 1.0, а третья часть VBSCRIPT.DLL/3 содержит обработчик MS Regular Expression 5.5. Лично я применяю регулярные выражения для анализа строк довольно часто. Ну вот, например, для анализа правильности IP-адреса.
У меня на сайте есть полная спецификация регулярных выражений, поддерживаемых .NET. Эта технология унифицирована в стандарте POSIX, и Microsoft-реализация полностью стандартна, однако наиболее широко распростаненная площадка этой технологии - PERL - существенно шире стандарта.
- Седьмая - технология построения трансляторов - применяется для лексического и синтаксического анализа строки путем ее разбиения на лексемы (терминальные и нетерминальные) с последующим анализом входной строки на основе таблицы переходов конечного автомата. Обычно эта технология используется при создании новых языков со сложной структурой либо для преобразования программы с одного языка на другой.
Наиболее совершенные системы этой категории, принимают описание языка в нотации Бэкуса-Науэра (определенной в RFC-2616), автоматически приводят грамматику языка с контекстно-свободному виду, обычно типа LL(1), и автоматически создают обработчик входного потока (транслятор), которых и будет преобразовывать входной символьный поток в выходной (в другой язык, в промежуточный язык, в машинный код, в XML и т.д.)
В NET есть даже специальное пространство имен System.Reflection.Emit, которое позволяет напрямую создавать (эмитировать) машинный код своей собственной прогой как компилятором. Такое мне писать еще не доводилось, но было бы интересно - работать с физической структурой сборок я пробовал не раз. Кстати, множество интегрированных сред, создающих машинный код по диаграммам классов, тоже использует именно это пространство имен.
Как альтернатива этой технологии может применяться создание специализированных языков на основе разбиения строк по правилам XML. Это позволяет отказаться от данной технологии для новых языков взаимодействия программ (взаимодействующих по протоколу SOAP, например) и свести задачу к первой из перечисленных технологий. Кроме того, в этом случае достаточно вновь созданный XML-язык зарегистрировать в XML.ORG и он станет общедоступным стандартом.
- Восьмая - Разнообразные вариации LZ-методов сжатия строк без потерь. В NET2005 входит стандартный (RFC 1952) компрессор . Он находится в пространстве имен System.IO.Compression. Как раз в момент написания этой странички у меня была задача распаковывания на лету XLS-прайс листов, скачиваемых из инета. Увы, меня ждало разочарование - на лету не получилось... Мучался я над этим вопросом несколько ночей, сначала пытался приспособить по PInvoke встроенную виндузовую расзиповку, но в итоге сделал свой интерфейс к вот этой сборке.
- Девятая - пакетное образование строк из реляционных данных SQL-сервером. Это достаточно новое и удивительное направление обработки данных, возникшее на стыке SQL и XML-технологий. Казалось бы, это не нужно совершенно, ибо реляционные технологии обеспечивают исчерпывающие возможности фильтрации/конкатенации данных. Однако, это только на первый взгяд. Я вкусил прелесть такой техники работы - когда на первом этапе данные фильтруются и грузятся всей массой в DataSet, а оттуда уже более тоненькими способыми - по XPATH - по чуть-чуть отбираются, скажем для заполнения TreeView, уже без дергания SQL-сервера. При правильной организации такая технология творит просто чудеса - то же динамическое заполнение TreeView выполняется буквально в пару строк.
Поскольку строки получаются из SQL практически XML-WelFormed (а в SQL2005 благодаря наличию тега ROOT - полностью WelFormed), то к ним на ходу можно применять, не только пятую (XPATH) технологию, но и первую технологию - XSLT-преобразование.
- Десятая - Еще один способ массовой генерации XML-форматированных строк - из обьекта DataSet. Фактически вот из такого обьекта DataSet (его вид в дизайнере, его схема) получается ПЯТЬ стандартных типов XML:
- DiffGram - в нем находятся все версии данных из DataSet: отредактированные, обновленные, удаленные, добавленные. Кстати существует новая и очень интересная техника программирования, когда этот DiffGram напрямую передается в виде текста SQL-процедуре, которая открывает его по OPENXML и производит ВСЕ модификации данных ЗА ОДИН ВЫЗОВ ПРОЦЕДУРЫ. Собственно, DS.Update так и работает, однако свое решение можно организовать гораздо более эффективно, например, в случае как в приведенном мною примере, когда огромный текст не меняется, а меняется лишь малое по размеру поле. Длинное поле можно в таком случае можно просто обрезать по XSLT и не обрабатывать вовсе. Оба эти способа обновления данных противоположны методам построчного обновления данных либо вызовами процедуры (как в проге выше) либо по DS.ROWS(i).Update. Еще один способ обновления данных - вообще без использования DataSet, в котором хранятся SQL-команды - простым вызовом CMD.
- Собственно текущее содержимое DS.
- Отдельно схема данных.
- Схема DS вместе с текущим содержимым.
- И, наконец, не весь DS, а содержимое отдельной таблы в нем.
- Одиннадцатая - XML-шаблоны (Templates) - это еще одно альтернативное место нижнего уровня доступа к данным (кроме SQL-процедур и DataSet). Такой способ организации нижнего уровня доступа к данным мне на практике применять пока не доводилось.
Апдейтаграммы и XML-шаблоны более подробно расписаны в справочнике к пакету - SQLXML. А для первоначального знакомства с этой проблематикой я рекомендую вот эту статью (оригинал).
- Двенадцатая - Как уже говорилось раньше, строки, производимые обьектом DataSet могут содержать структуру сетки, те формат данных. Эта тема мне очень близка. Работая в компании Сириус, я столкнулся с самодельной надстройкой над MsFlexGrid, в которой автор пытался реализовать часть первоначальной функциональности GridView. Microsoft взяла у компании, ныне называющейся ComponentOne, сетку, которую упростив до предела и обозвав MsFlexGrid стала поставлять в составе VB6. К сожалению, исходную функциональность обрезали настолько, что сетка MsFlexGrid перестала выполнять и онлайновой редактирование данных, и отображение рисунков, чекбоксов, комбешников и пр. Только позже в микрософте одумались и восcтановили в DataGridView всю эту функциональность. Так вот, тот программер из компании Сириус не стал брать исходный GridView от ComponentOne или использовать любую другую сетку (в том числе и новую от Microsoft), а решил сам восстановить функциональность MsFlexGrid хотя бы на половину от исходного GridView. Эта идея отняла у него примерно шесть лет, но до ума дело он так и не довел. Мне попала в руки эта сетка в том виде, когда она даже форматы столбцов не позволяла перезагружать без полной перекомпиляции проекта.
Я написал к его сетке интерфейс в виде нескольких VB6-прог и SQL-процедур, а также фабрику, производящую таблы с форматами столбцов для его сетки. Жаль, что столько труда было потрачено им впустую, ведь теперь микрософт восстановил первоначальную функциональность сетки и DataGridView отображает и комбешники и графику и онлайновое редактирование и даже форматы столбцов прекрасно сохраняет/перезаписывает в одно-единственное действие, если, конечно, сетка связана с данными.
- Триннадцатая - Радикальная идея NET в том, что КАЖДЫЙ обьект имеет стандартный сериализатор в строку, который вызывается методом .ToString. Такая радикальная идея имеет двойное практическое применение. С одной стороны - это техника .Net Remoting, при которой параметры могут легко передаватся при вызовах удаленно расположенных фрагментов программы, а с другой стороны - отдельно взятый SOAP-форматер - это основа совершенно новой техники - WEb-служб. Ну а с третьей стороны - это сериализаторы собственных обьектов.
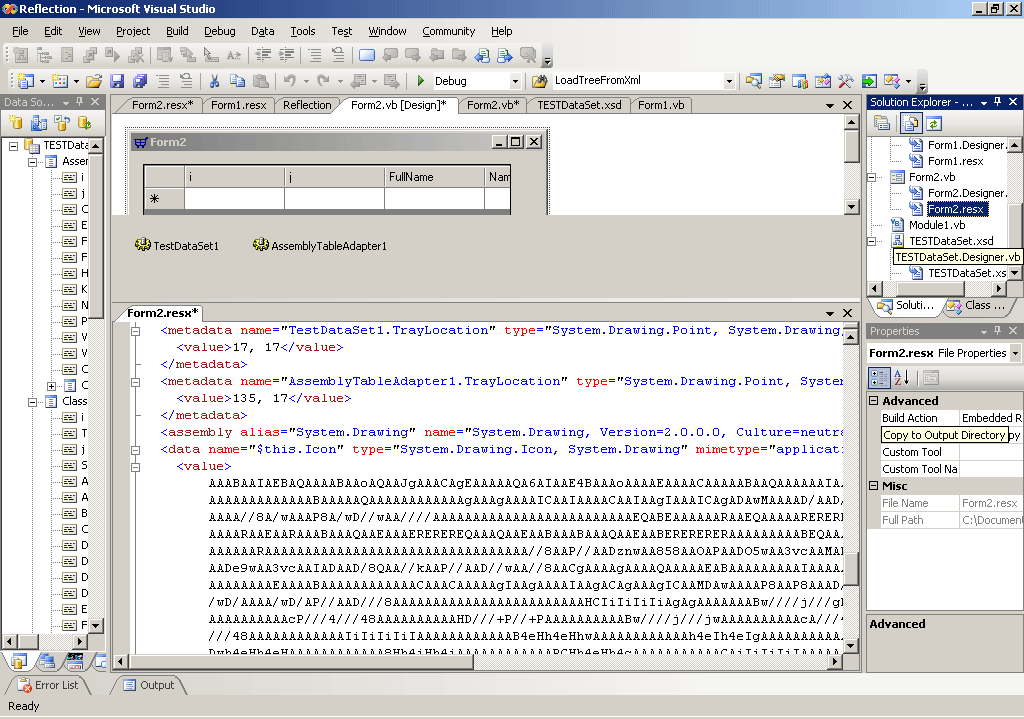
- Четырнадцатая - Еще одна спецтехника порождения строк, в общем-то идентичная SOAP-форматеру, но применяемая к рисункам и бинарным кодам - сериализация их преобразованием BASE64. В этой технике работает сама NET-студия. Вот я добавил на форму иконку, и она была тут же сохранена в ResX-файл этим преобразованием. Я тоже пару раз использовал эту технику при сохранении рисунков, импортированных из прайс-листов. Для этого надо воспользоватся преобразованием System.Xml.XmlTextWriter.ReadBase64 / System.Xml.XmlTextReader.ReadBase64.
- Пятнадцатая - Стандартный сериализатор значений DataTime в строку в XML - SoapFormater решает это корректно, но если преобразовывать даты в лоб самому по Format$ (что характерно для Access-программистов), то надо как минимум сначала переустановить SET DateFormat для SQL-сервера.
- Шестнадцатая - Создание криптографических потоков строк. Тема эта большая и состоит не только из System.Security.Cryptography.CryptoStream, как многие думают. Даже XML бывают шифрованными. Когда-нибудь я соберусь с силами и распишу эту тему подробнее, а пока у меня на сайте можно посмотреть кое-какие мои программки с применением криптографии: ParmProtector, быстрый расчет ХЕШ кодов файлов, запоминание в реестре шифрованных паролей, встроенные в ASP2 возможности, а также реализацию криптографии в смарт-картах.
- Семнадцатая - Создание строк из потоков последовательно расположенных в памяти байтов. Операции с графикой, передачи по сетям - это все работа с байтовыми последовательностями. Вот пример правильного преобразования потока MemoryStream, возникшего от сериализации датасета, в строку.
- Восемнадцатая - Ну и наконец, последняя техника преобразования строк, о которой я упомяну здесь - это обыкновенная перекодировка ANSI/UTF-8/UTF-7 и тд. Я столкнулся с необходимости применения этой техники даже при написании своей самой первой опытно-экспериментальной проги еще на самой первой версии NET. А вот такой текстик из MSDN в пространстве имен System.Text должен вам выдать примерно такую табличку всех поддерживаемых на вашем компе кодировок строк.
{kind=link}
Тот, кто дочитал эту страницу до конца, уже никогда не будет говорить, что обработка строк - это так, ерунда. &, InStr, Mid, Split, Format$ и тд - как все это далеко от вышеописанных СПЕЦИАЛИЗИРОВАННЫХ И ПРОДВИНУТЫХ ТЕХНОЛОГИЙ ОБРАБОТКИ СТРОК! И вообще сама по себе тема переработки строк почему-то не поднимается в явном виде, в отличие от переработки реляционных данных, например. И заметьте, что обрабатываемые по многих вышеперечисленным технологиям строки не обязательно должны быть XML-форматированными.
Вот еще некоторые статьи, которые привлекли мое внимание:
- XML на практике в .NET Framework,
- Пример создания многоязыкового приложения (XML)
- XML: опыт безопасного написания документов и приложений
- Понимание пространств имен XML
- URI, URL и URN
- Как выбрать наиболее подходящую базу данных для XML-приложения
NetCommon context:
 )
)
|
|