Life without local filesystem. Uploader to Cloudflare D1 from Cloudflare KV.
Deno, Bun and Node has local filesystem, but Cloudflare has no local filesystem.
But, of course, for any Worker we must hav huge data, for example like this:
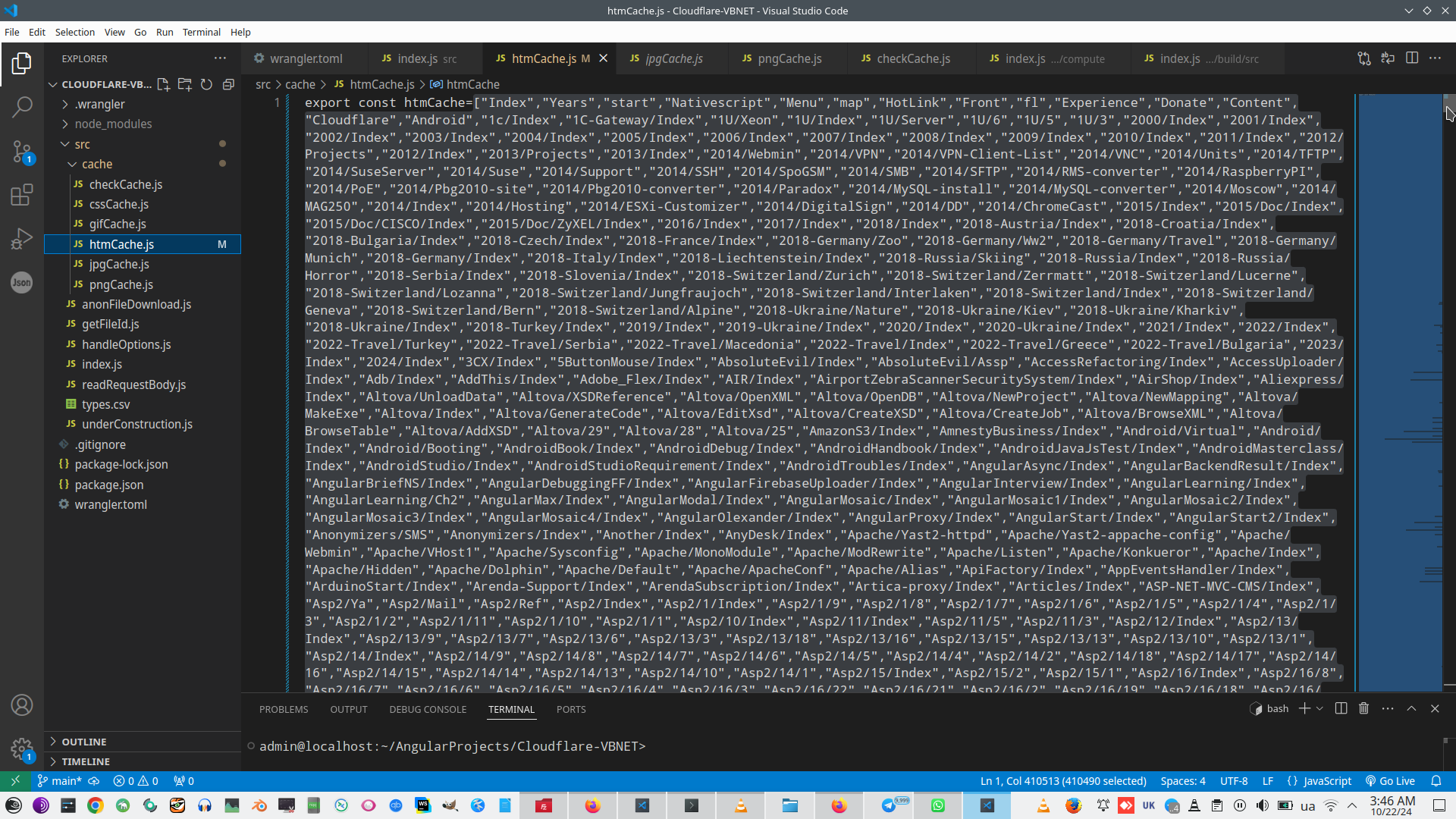
And this is a reason why we need to make optimization like this 9. Reduce worker size.
And for more and more large data this is impossible at all
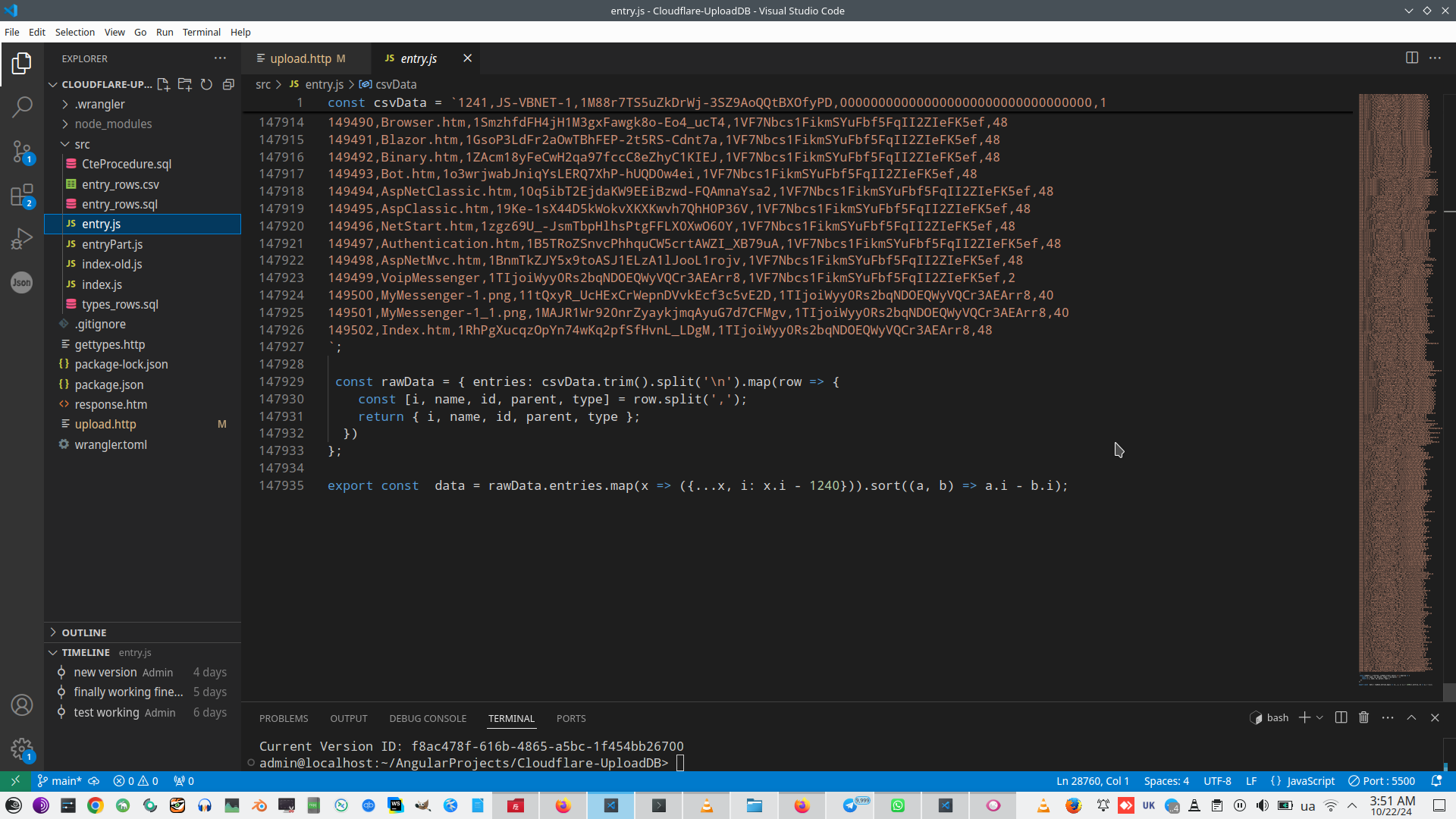
And, of course, if data changing, we need constantly and permanently redeploy data. This is not a normal case, of course.
Fortunately, in Cloudflare we have special opportunity to store data - Cloudflare KV, this is my workable template to use this opportunity - https://github.com/Alex1998100/CloudflareKV.
So, this is my final solution with load data from KV storage to D1 database https://github.com/Alex1998100/CloudflareD1
index.js
1: //https://developers.cloudflare.com/d1/get-started/
2: //https://everythingcs.dev/blog/cloudflare-d1-workers-rest-api-crud-operation/
3: //https://workers-qb.massadas.com/databases/cloudflare-d1/
4: //https://developers.cloudflare.com/d1/tutorials/import-to-d1-with-rest-api/
5:
6: async function getDataPortion(env) {
7: let csvData = await env.cache_dev.get("dataPart")
8: const rawData = { entries: csvData.trim().split('\n').map(row => {
9: const [i, name, id, parent, type] = row.split(',');
10: return { i, name, id, parent, type };
11: })
12: };
13: return rawData.entries.map(x => ({...x, i: x.i - 1240})).sort((a, b) => a.i - b.i);
14: }
15:
16:
17: async function uploadData(env, data, endID) {
18: //Slicing the Array: data.slice is used to reduce the work done, including only the records after the endID record.
19: const recordsToInsert = data.slice(data.findIndex(x => x.id === endID) + 1)
20: // This executes all the database insertion Promises concurrently, significantly speeding up the process,
21: return Promise.all(recordsToInsert.map(async x => {
22: const sqlQuery = env.MY_TOPIC.prepare(
23: "INSERT INTO entry (i, name, id, parent, type) values (?,?,?,?,?)"
24: ).bind(x.i, x.name, x.id, x.parent, x.type);
25: try {
26: const { success } = await sqlQuery.run();
27: if (!success) {
28: console.log(`Error inserting record: ${JSON.stringify(x)}`);
29: }
30: } catch (error) {
31: console.error(`Error inserting record: ${JSON.stringify(x)}, error: ${error}`);
32: }
33: }));
34: }
35:
36: export default {
37: async fetch(request, env) {
38: const { pathname } = new URL(request.url);
39: console.log(pathname);
40: if (pathname === "/types") {
41: const { results } = await env.MY_TOPIC.prepare(
42: 'SELECT * FROM "types";',
43: ).all();
44: return Response.json(results);
45: } else if (pathname.startsWith("/upload")) {
46: const endID = pathname.split("/")[2];
47: if (!endID) {
48: return new Response("No ID specified", { status: 400 });
49: }
50: try {
51: const data = await getDataPortion(env);
52: console.log(data)
53: await uploadData(env, data, endID);
54: return new Response("ok");
55: } catch (error) {
56: console.error("Upload failed:", error);
57: }
58: return new Response("ok");
59: }
60: return new Response(
61: "Request error",
62: );
63: },
64: };
wrangler.toml
1: name = "uploaddatabase"
2: main = "./src/index.js"
3: account_id = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
4: compatibility_date = "2024-11-11"
5: compatibility_flags = [ "nodejs_compat" ]
6: [[d1_databases]]
7: binding = "MY_TOPIC"
8: database_name = "topic"
9: database_id = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
10: [[kv_namespaces]]
11: binding = "cache_dev"
12: id = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
13: preview_id = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
Unfortunately I don't know why this loader require fantastic time to load data, but this not time for read data from KV, this is data to insert data to D1, its look as D1 storage has extremely low performance and extremely high response time. It's sad, I hope Cloudflare will do something with his D1 performance.
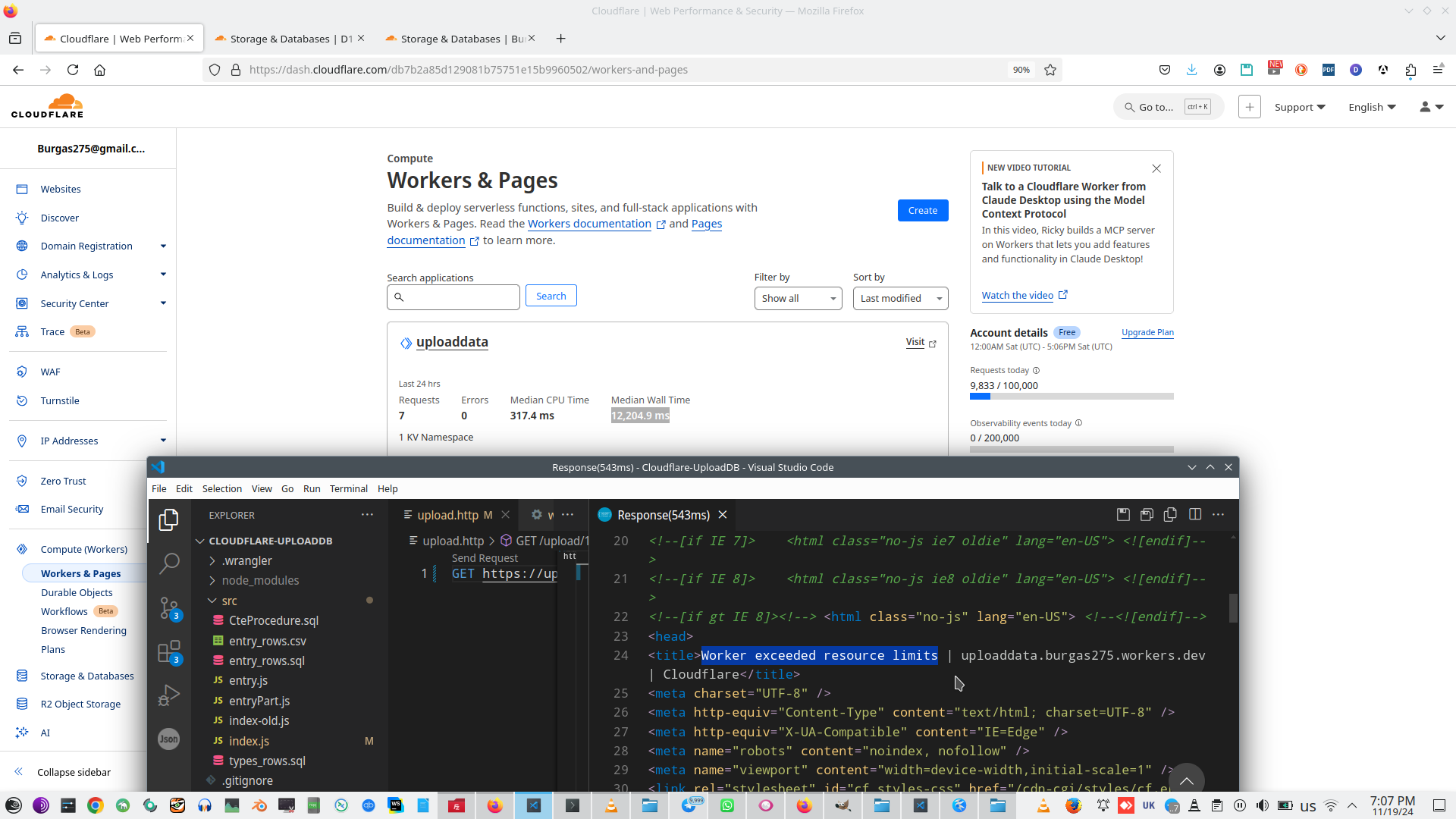
Cloudflare context:
 )
)
|
|